Critiques of NHST
Code
mu = 17.7; sigma = 3.2; n = 9; xbar = 19.1
sem = sigma/sqrt(n)
cv_pos = mu + 1.96*sem
cv_neg = mu - 1.96*sem
zstat = (xbar-mu)/sem
lower_bound = mu-3*sem
upper_bound = mu+3*sem
data.frame(M = c(lower_bound:upper_bound)) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "line") +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area", fill = "purple", xlim = c(cv_pos, upper_bound)) +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area", fill = "purple", xlim = c(lower_bound, cv_neg)) +
geom_vline(aes(xintercept = xbar), color = "red", linetype = "dashed") +
scale_x_continuous(breaks = round(c(lower_bound:upper_bound))) +
labs(x = "Mean", y = "density", title = "Sampling distribution in original scale")+
theme_pubr()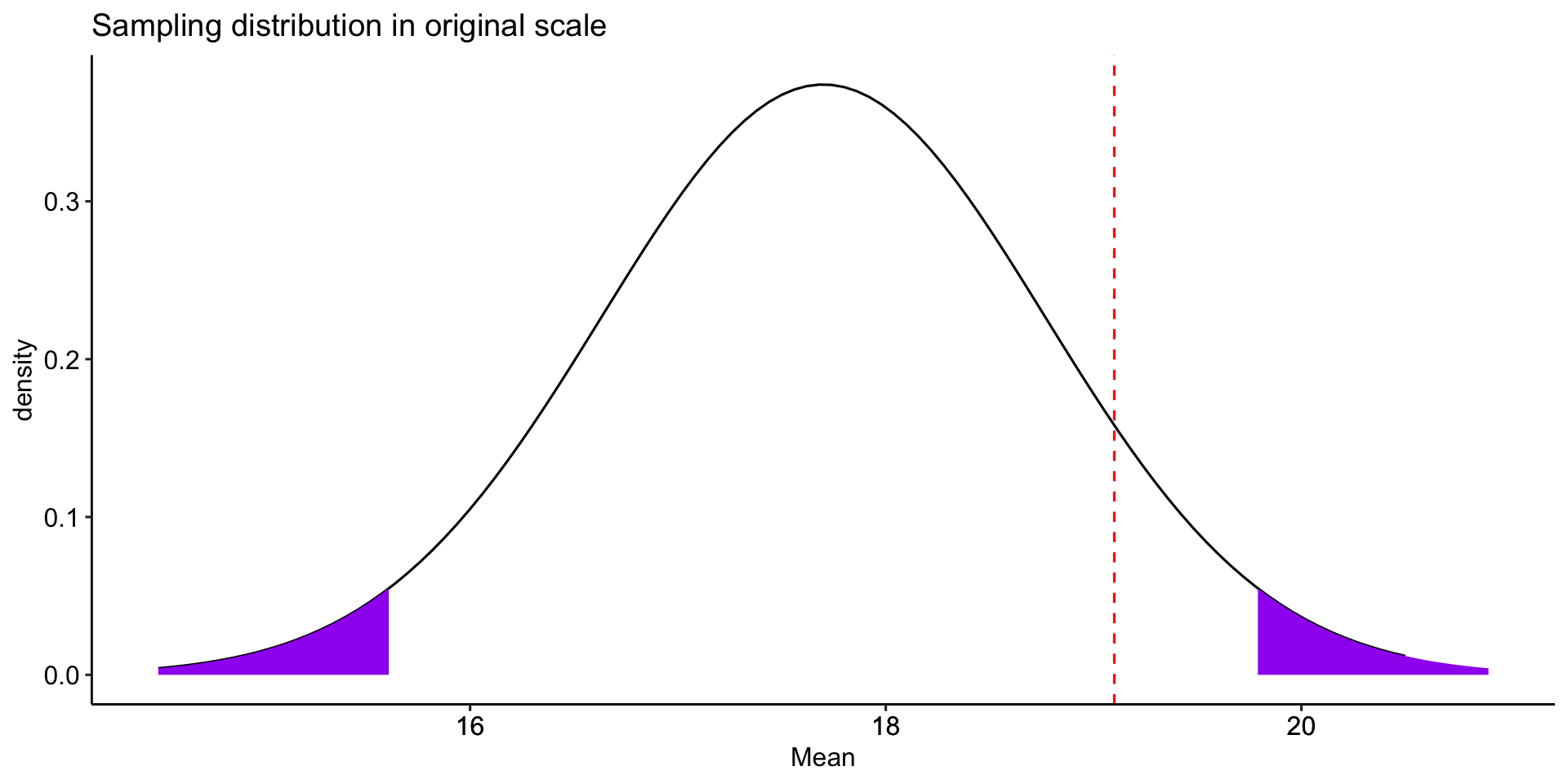
Code
data.frame(M = c(-3:3)) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x),
geom = "line") +
stat_function(fun = function(x) dnorm(x),
geom = "area", fill = "purple", xlim = c(1.96, 3)) +
stat_function(fun = function(x) dnorm(x),
geom = "area", fill = "purple", xlim = c(-3, -1.96)) +
geom_vline(aes(xintercept = zstat), color = "red", linetype = "dashed") +
scale_x_continuous(breaks = c(-3:3)) +
labs(x = "Z-statistic", y = "density", title = "Sampling distribution in Z-statistic units")+
theme_pubr()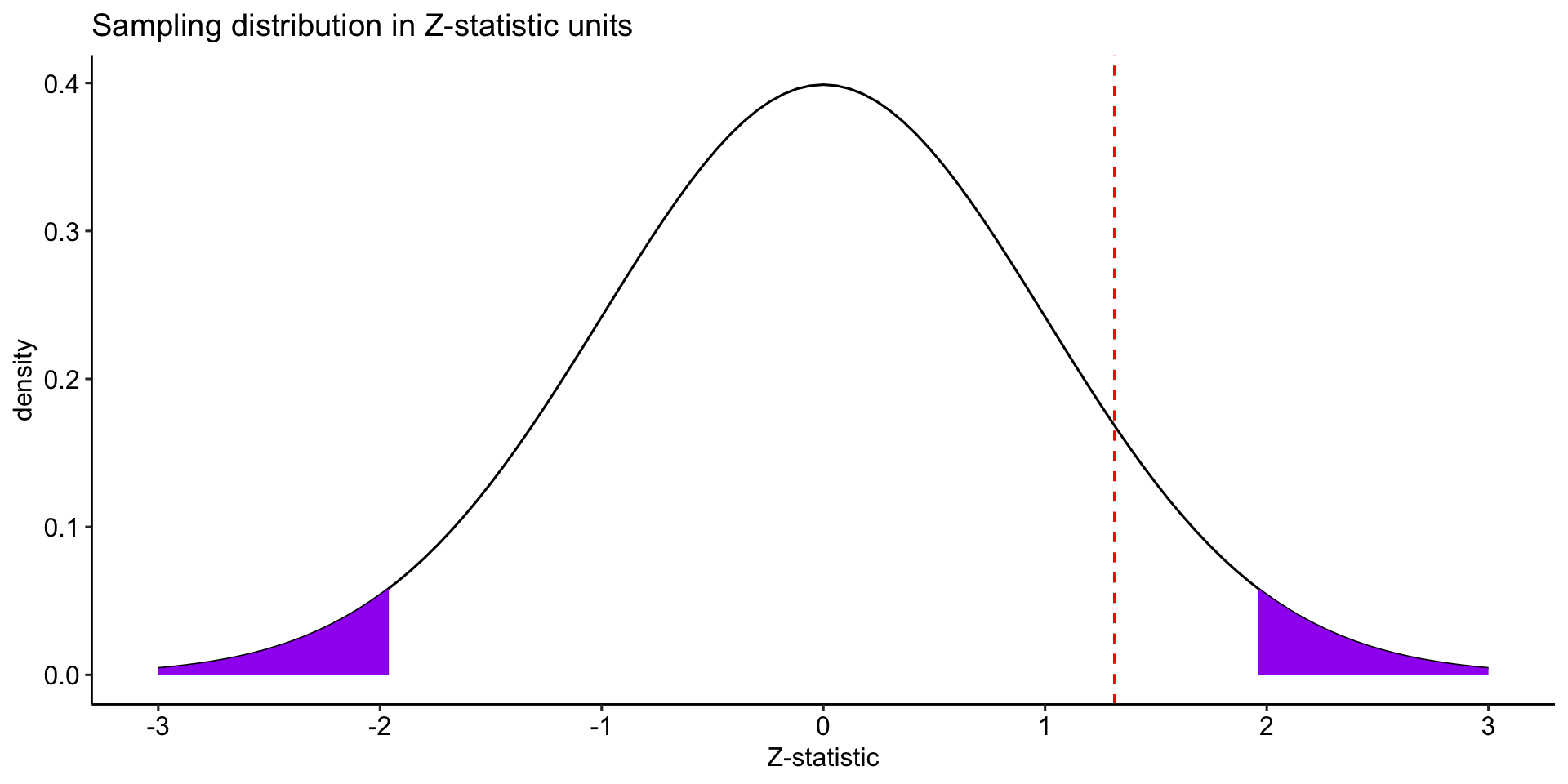
The probability of getting this sample mean in this sampling distribution is:
Recap
You can test the hypothesis by comparing the sample mean \((\bar{X})\) to the mean under the null hypothesis \((\mu_0)\).
Alternatively, you can compare the the mean under the null hypothesis \((\mu_0)\) to the the sample mean \((\bar{X})\).
Code
mu = 17.7; sigma = 3.2; n = 9; xbar = 19.1
sem = sigma/sqrt(n)
cv_pos = xbar + 1.96*sem
cv_neg = xbar - 1.96*sem
zstat = (xbar-mu)/sem
lower_bound = mu-3*sem
upper_bound = xbar+3*sem
data.frame(M = c(lower_bound:upper_bound)) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x, mean = xbar, sd = sem),
geom = "line") +
stat_function(fun = function(x) dnorm(x, mean = xbar, sd = sem),
geom = "area", fill = "purple", xlim = c(cv_pos, upper_bound)) +
stat_function(fun = function(x) dnorm(x, mean = xbar, sd = sem),
geom = "area", fill = "purple", xlim = c(lower_bound, cv_neg)) +
geom_vline(aes(xintercept = mu), color = "red", linetype = "dashed") +
scale_x_continuous(breaks = round(c(lower_bound:upper_bound))) +
labs(x = "Mean", y = "density", title = "Sampling distribution around sample mean")+
theme_pubr()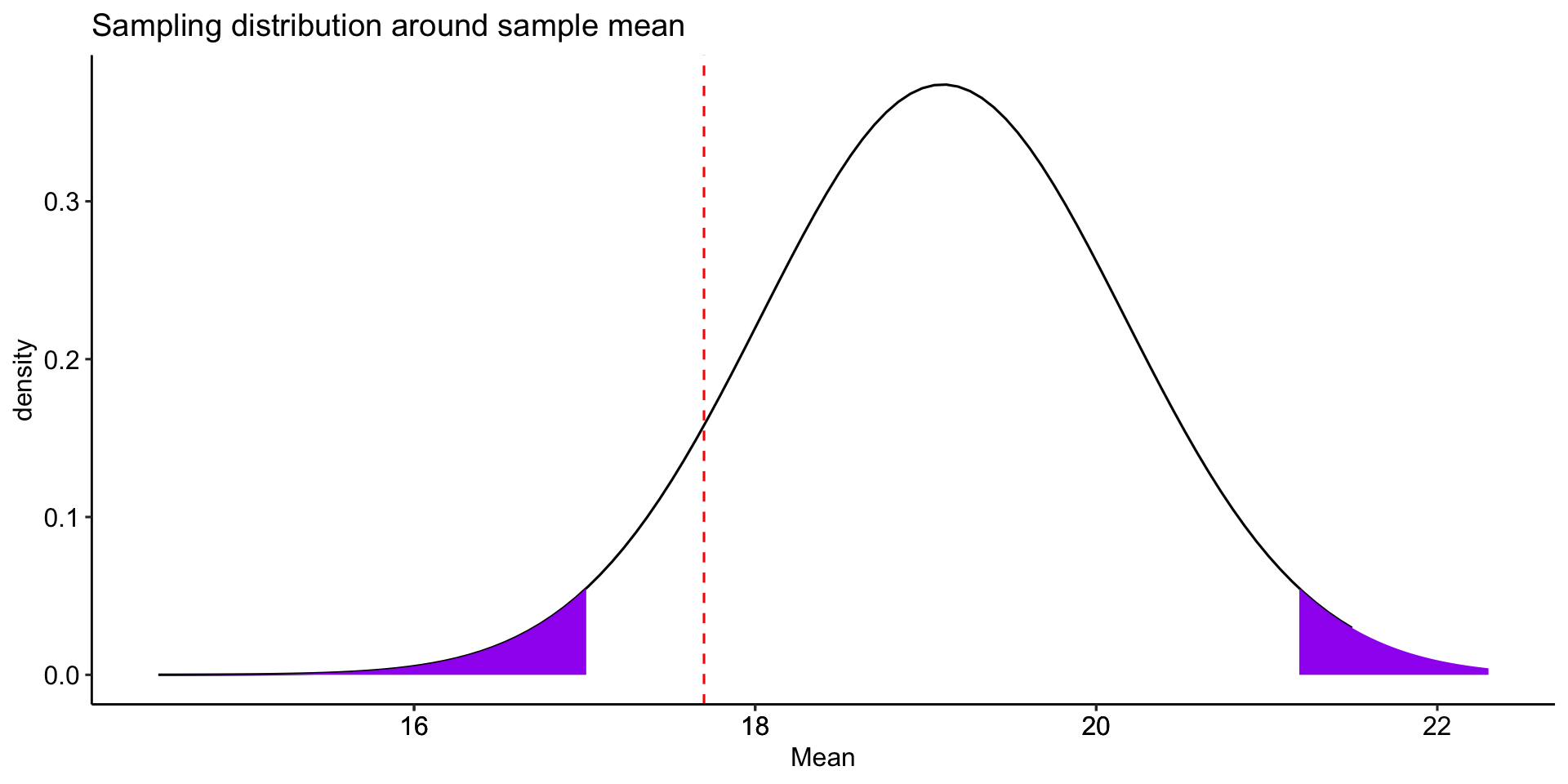
Code
mu = 17.7; sigma = 3.2; n = 9; xbar = 19.1
sem = sigma/sqrt(n)
cv_pos = mu + 1.96*sem
cv_neg = mu - 1.96*sem
zstat = (xbar-mu)/sem
lower_bound = mu-3*sem
upper_bound = mu+3*sem
data.frame(M = c(lower_bound:(upper_bound+5))) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "line") +
stat_function(aes(fill = "Type I error"), fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area", xlim = c(cv_pos, upper_bound),
alpha = .5) +
stat_function(aes(fill = "Type I error"), fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area", xlim = c(lower_bound, cv_neg),
alpha = .5) +
stat_function(fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "line") +
geom_vline(aes(xintercept = cv_pos, color = "Type I error")) +
scale_x_continuous(breaks = seq(14,26,2), limits = c(14,26)) +
guides(color = "none") +
labs(x = "Mean", y = "density", title = "Sampling distribution in original scale", fill = NULL)+
theme_pubr()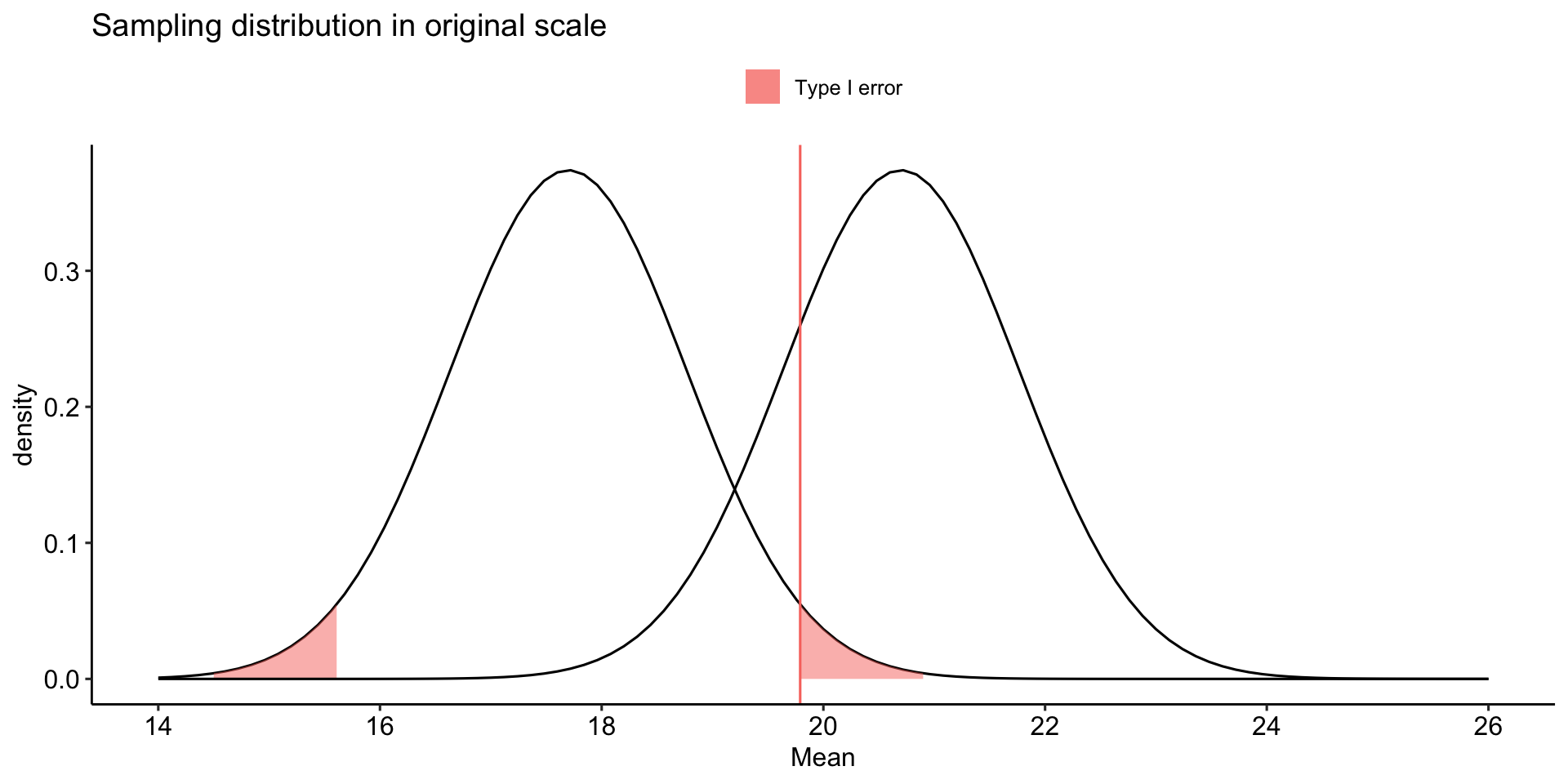
Code
data.frame(M = c(lower_bound:(upper_bound+5))) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "line") +
stat_function(aes(fill = "Type II error"), fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "area", xlim = c(lower_bound, cv_pos),
alpha = .5) +
stat_function(aes(fill = "Power"), fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "area", xlim = c(cv_pos, upper_bound+5),
alpha = .5) +
stat_function(fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "line") +
geom_vline(aes(xintercept = cv_pos, color = "Type I error")) +
scale_x_continuous(breaks = seq(14,26,2), limits = c(14,26)) +
scale_fill_brewer(palette = "Dark2") +
guides(color = "none") +
labs(x = "Mean", y = "density", title = "Sampling distribution in original scale", fill = NULL)+
theme_pubr()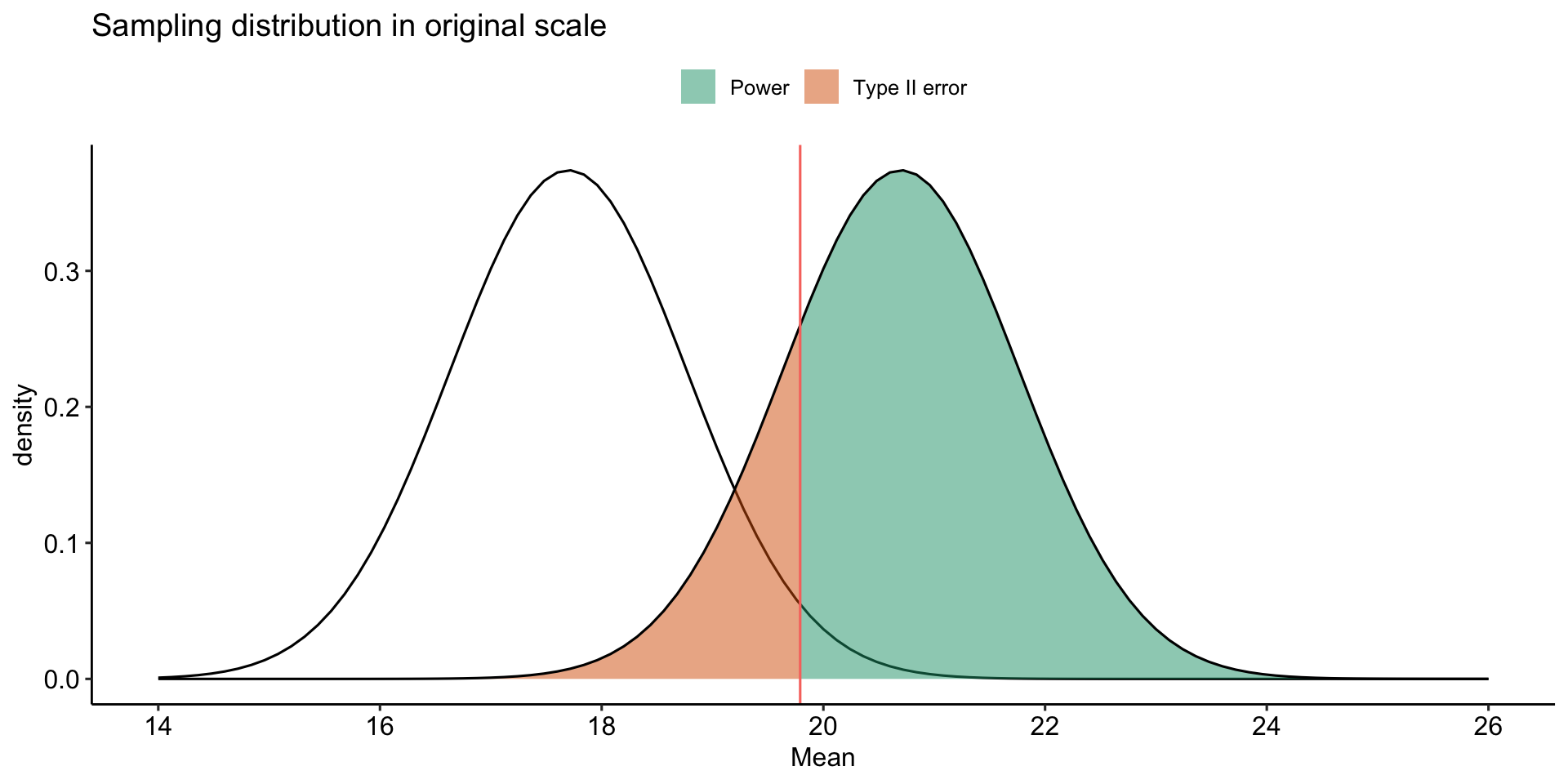
How can power be increased?
Code
data.frame(M = c(lower_bound:(upper_bound+5))) %>%
ggplot(aes(x = M)) +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "line") +
stat_function(fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "line") +
stat_function(aes(fill = "Type I error"),
fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area",
xlim = c(cv_pos, upper_bound),
alpha = .5) +
stat_function(aes(fill = "Type I error"),
fun = function(x) dnorm(x, mean = mu, sd = sem),
geom = "area",
xlim = c(lower_bound, cv_neg),
alpha = .5) +
stat_function(aes(fill = "Type II error"),
fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "area",
xlim = c(lower_bound, cv_pos),
alpha = .5) +
stat_function(aes(fill = "Power"),
fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "area",
xlim = c(cv_pos, upper_bound+5),
alpha = .5) +
stat_function(fun = function(x) dnorm(x, mean = mu+3, sd = sem),
geom = "line") +
geom_vline(aes(xintercept = cv_pos,
color = "Type I error")) +
#scale_x_continuous(breaks = c(14:26), limits = c(14:26)) +
scale_fill_brewer(palette = "Dark2") +
guides(color = "none") +
labs(x = "Mean",
y = "density",
title = "Sampling distribution in original scale",
fill = NULL)+
theme_pubr()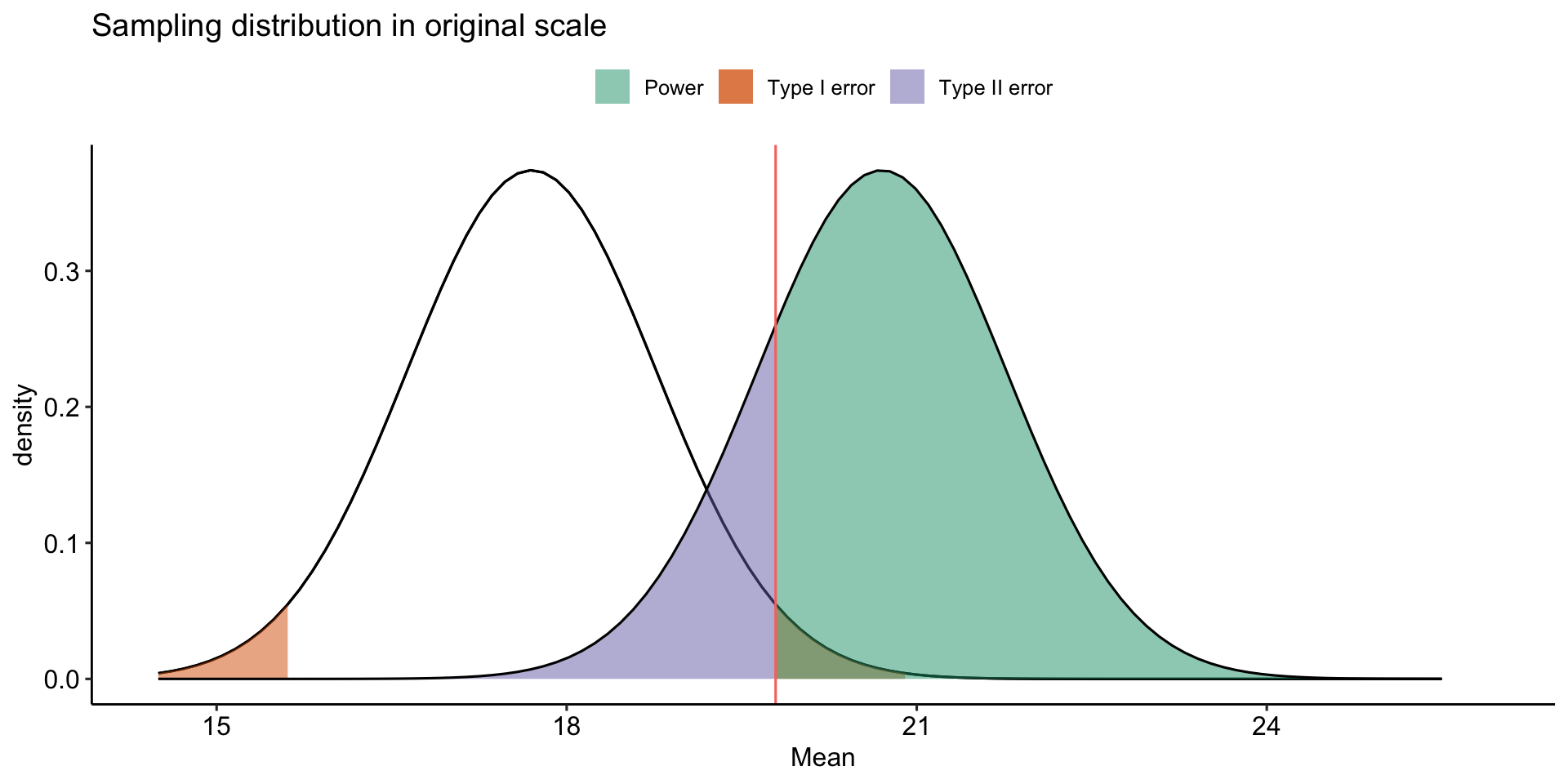
\[Z_1 = \frac{CV_0 - \mu_1}{\frac{\sigma}{\sqrt{N}}}\]
- increase \(\mu_1\)
- decrease \(CV_0\)
- increase \(N\)
- reduce \(\sigma\)
Here is a nice blog post about power & confidence intervals.
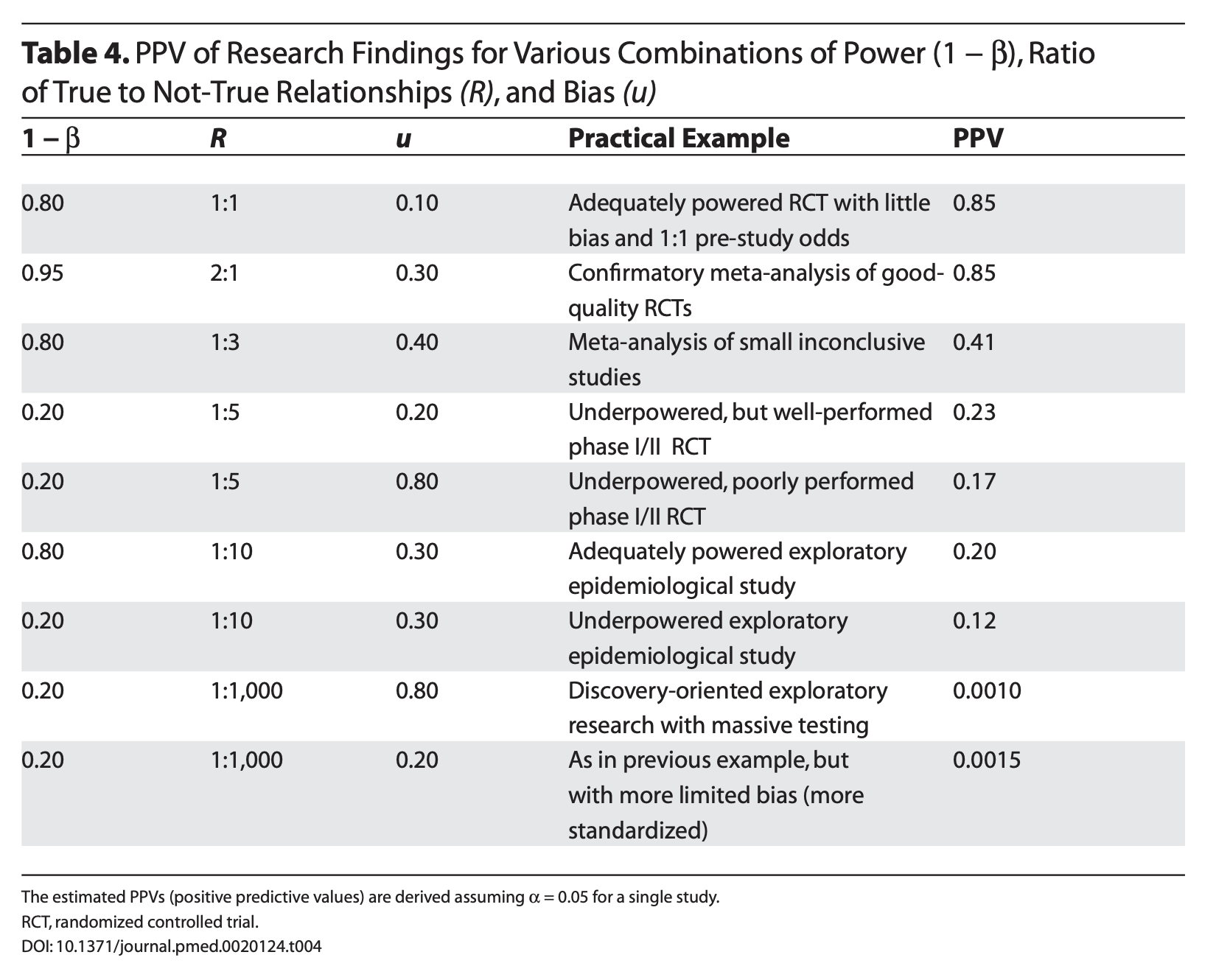
Let’s make some assumptions. If psychology studies use \(\alpha = .05\) and are good at achieving adequate power ( \(1-\beta = .80\) ), how does the choice of hypothesis affect PPV?
Code
ppv_fun = function(R, beta = .20, alpha = .05){
ppv = ((1-beta)*R)/((1-beta)*R + alpha)
return(ppv)
}
data.frame(prob = seq(0,1, by = .01)) %>%
mutate(ratio = prob/(1-prob),
ppv = ppv_fun(ratio)) %>%
ggplot(aes(x = prob, y = ppv)) +
geom_line() +
scale_x_continuous(expression("Probability that"~H[1]~"is true")) +
scale_y_continuous("Positive Predictive Value")+
theme_pubr(base_size = 20)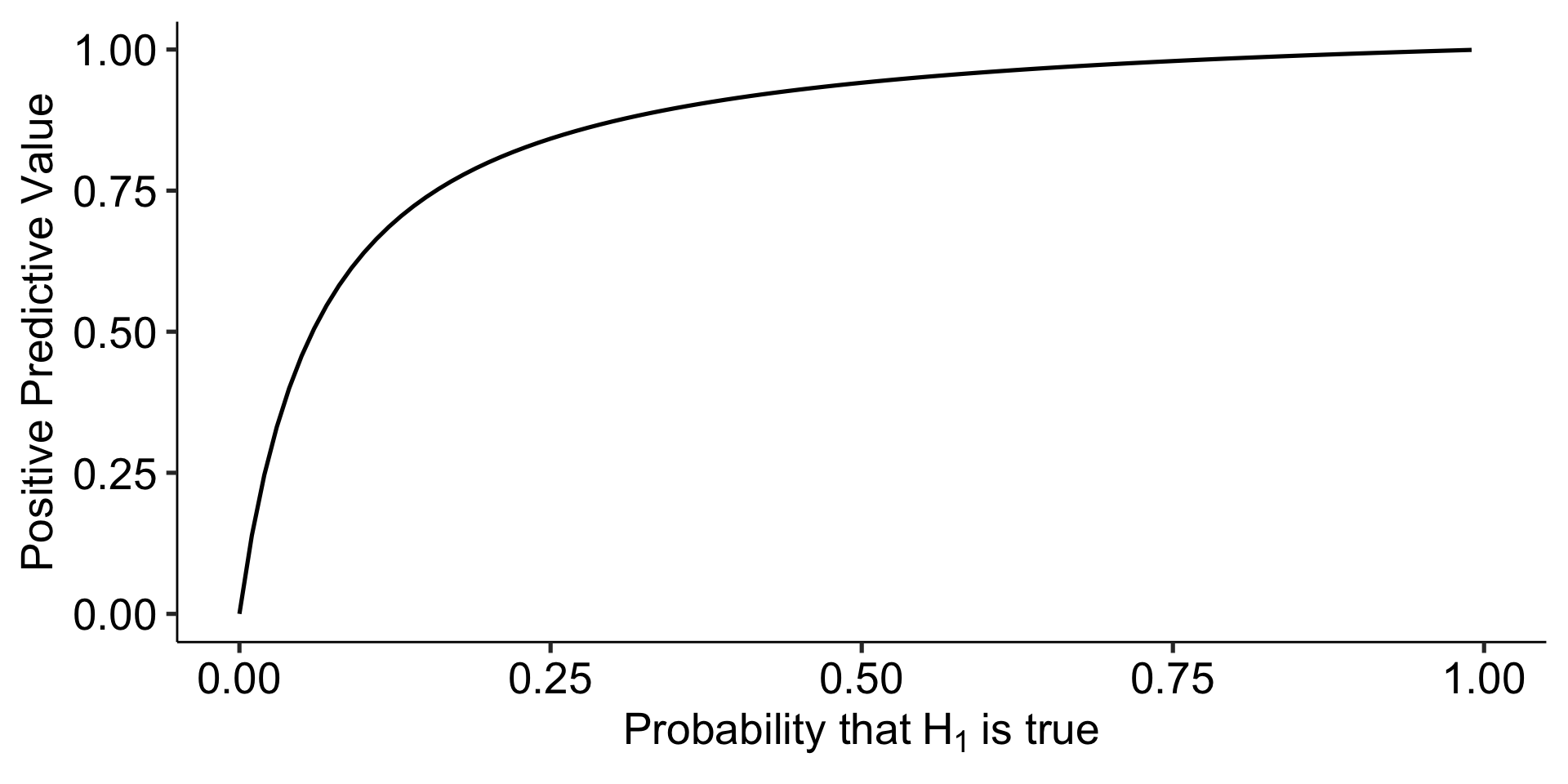
However, there are many reasons to think that psychology studies are underpowered. Typical power may be closer to .5 or even worse.
Code
data.frame(prob = seq(0,1, by = .01)) %>%
mutate(ratio = prob/(1-prob),
ppv = ppv_fun(ratio),
ppv_low = ppv_fun(ratio, beta = .5)) %>%
ggplot(aes(x = prob)) +
geom_line(aes(y = ppv, color = ".80")) +
geom_line(aes(y = ppv_low, color = ".50")) +
scale_x_continuous(expression("Probability that"~H[1]~"is true")) +
scale_y_continuous("Positive Predictive Value")+
scale_color_discrete("Power")+
theme_pubr(base_size = 20)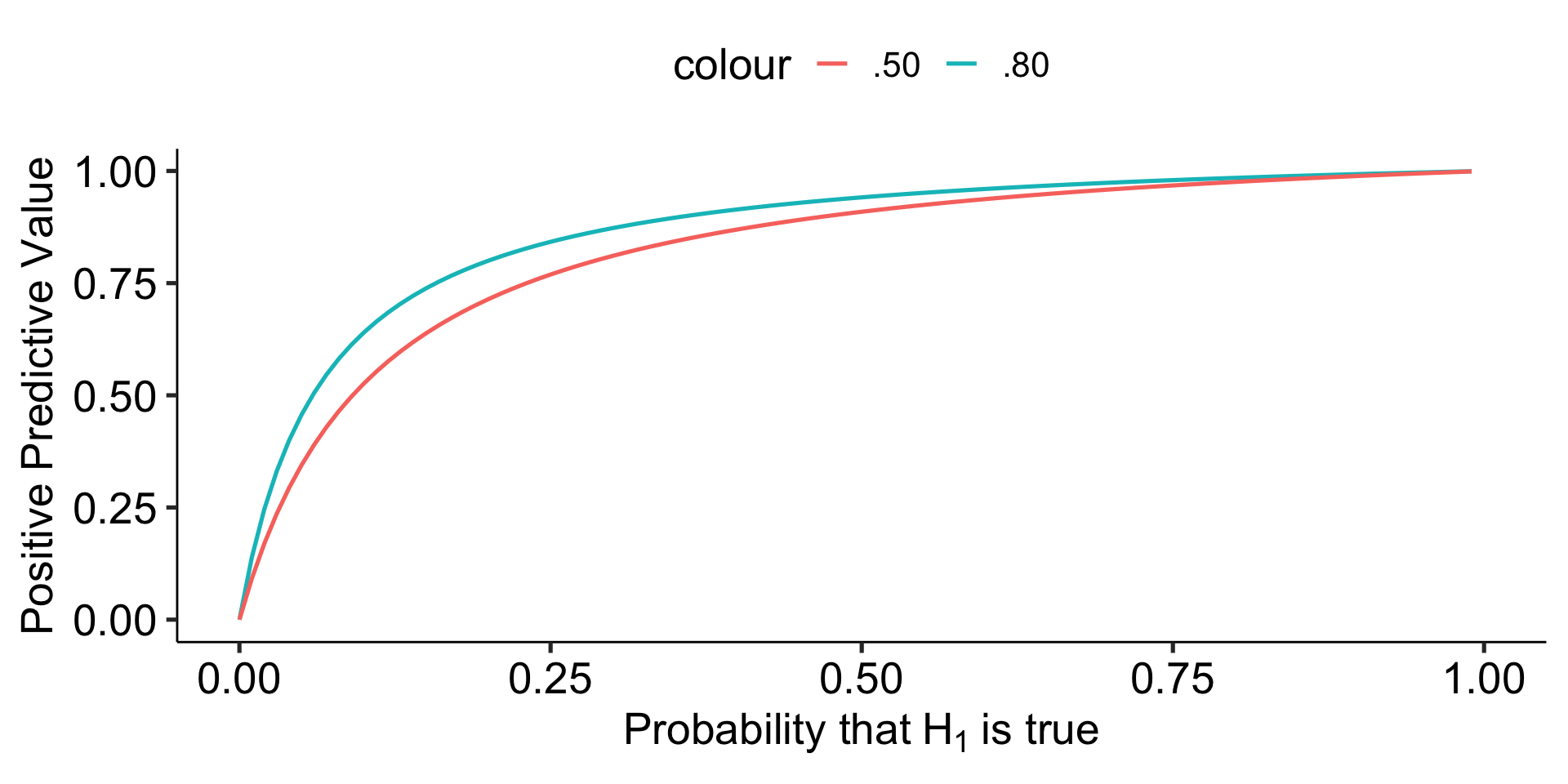
In addition to being under-powered, there’s recognition that research practices have inflated family-wise error, making \(\alpha\) much bigger than it should be.
Code
data.frame(prob = seq(0,1, by = .01)) %>%
mutate(ratio = prob/(1-prob),
ppv = ppv_fun(ratio),
ppv_low = ppv_fun(ratio, beta = .5),
ppv_alp = ppv_fun(ratio, alpha = .20),
ppv_low_alp = ppv_fun(ratio, beta = .5, alpha = .20)) %>%
ggplot(aes(x = prob)) +
geom_line(aes(y = ppv, color = ".80", linetype = ".05")) +
geom_line(aes(y = ppv_low, color = ".50", linetype = ".05")) +
geom_line(aes(y = ppv_alp, color = ".80", linetype = ".20")) +
geom_line(aes(y = ppv_low_alp, color = ".50", linetype = ".20")) +
scale_x_continuous(expression("Probability that"~H[1]~"is true")) +
scale_y_continuous("Positive Predictive Value")+
scale_color_discrete("Power")+
scale_linetype_discrete("Alpha") +
theme_pubr(base_size = 20)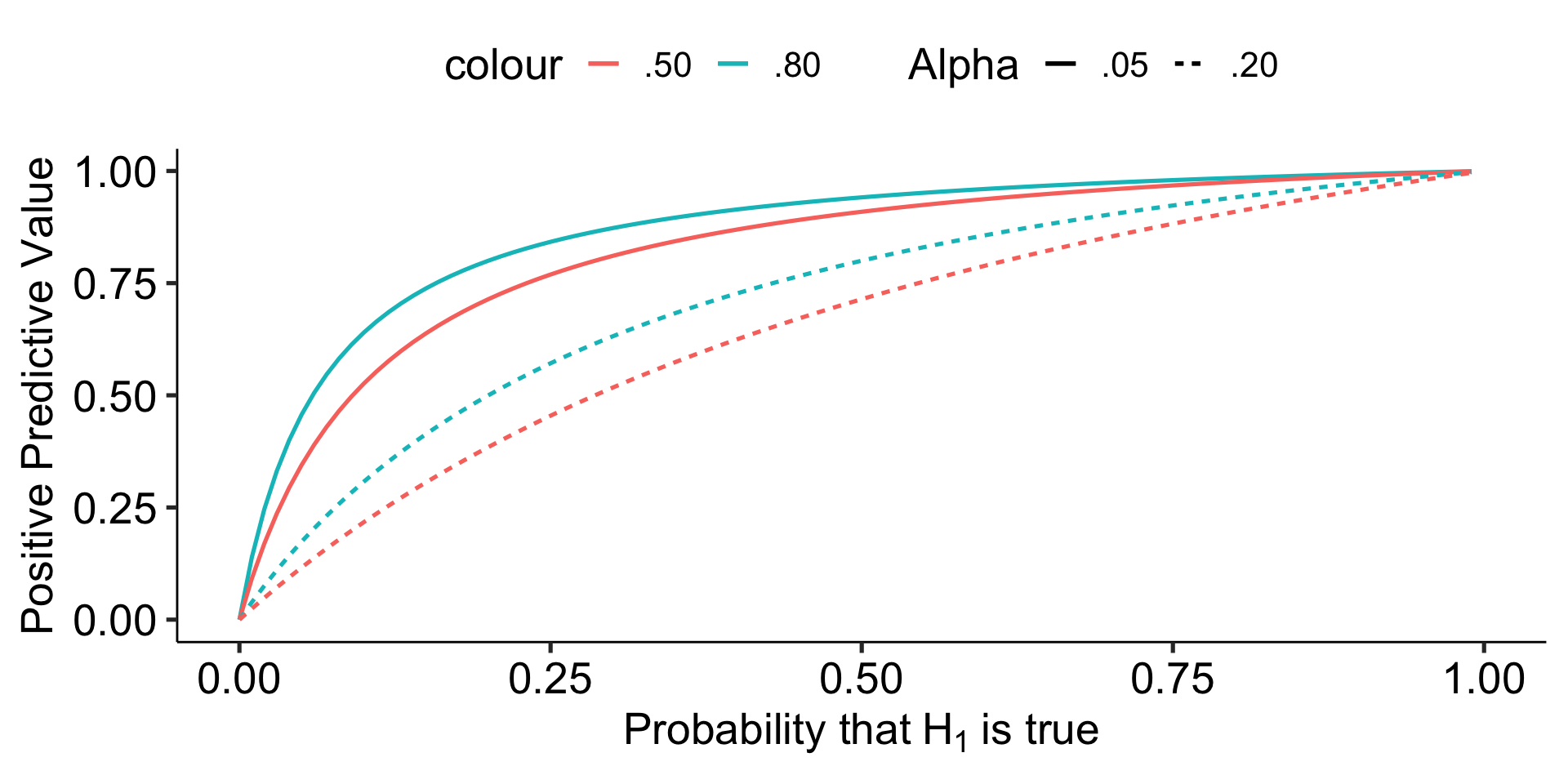
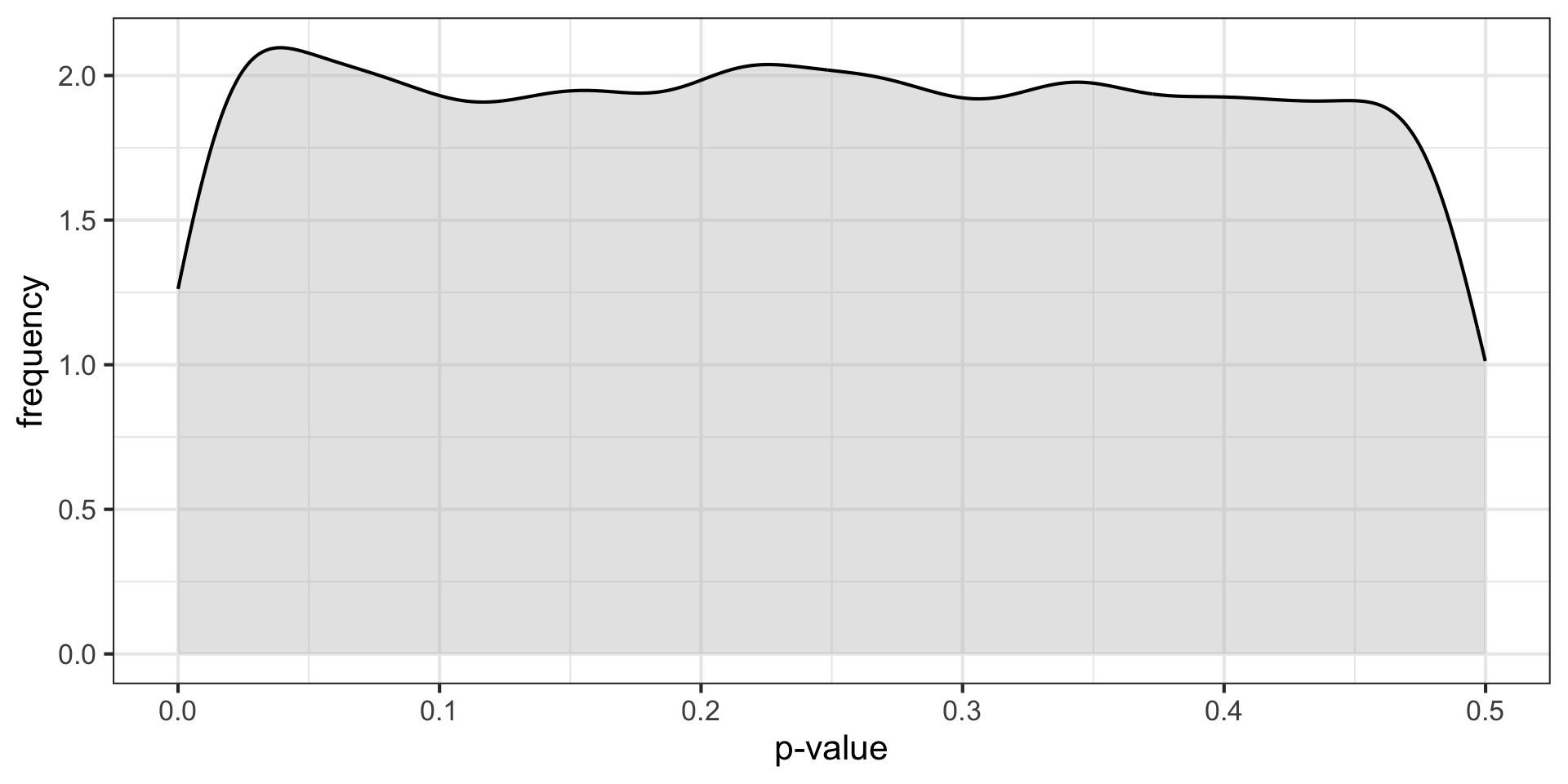
Each time I see how a decision affected my result, I am rolling the dice again.
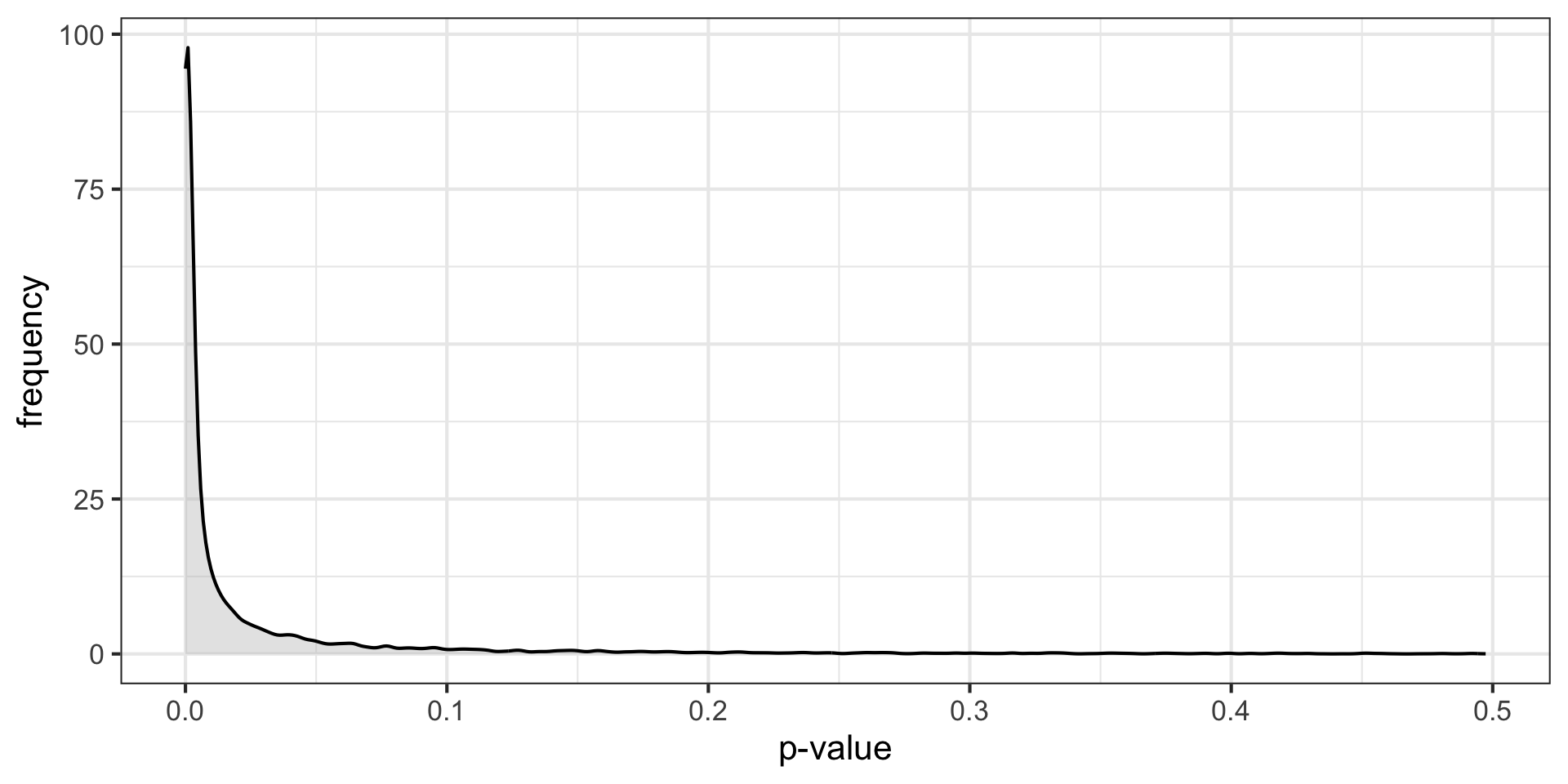
\(H_0\) true \((N = 30, \mu = 0, \sigma = 1)\)
Code
set.seed(201112)
# number of simulations
sims = 10000
# sample size
N = 30
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
# draw sample
sample = rnorm(n = N,
mean = 0,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
p_values[i] = sample_p
}
\(H_O\) false \((N = 30, \mu = 0.25, \sigma = 1)\)
Code
set.seed(201112)
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
# draw sample
sample = rnorm(n = N,
mean = .25,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
p_values[i] = sample_p
}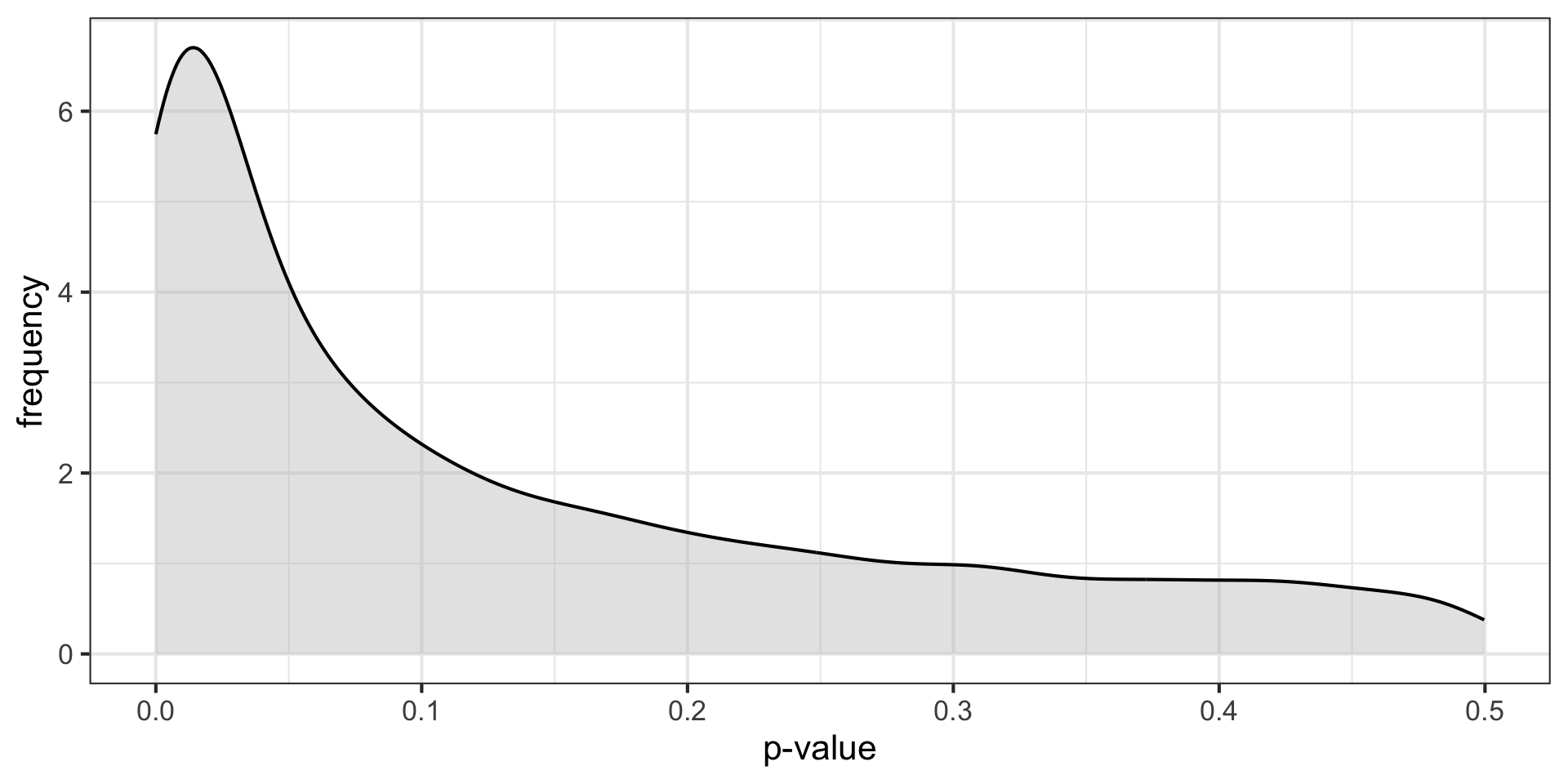
\(H_O\) false \((N = 30, \mu = 0.50, \sigma = 1)\)
Code
set.seed(201112)
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
# draw sample
sample = rnorm(n = N,
mean = .50,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
p_values[i] = sample_p
}
\(H_O\) false \((N = 30, \mu = 0.50, \sigma = 1)\)
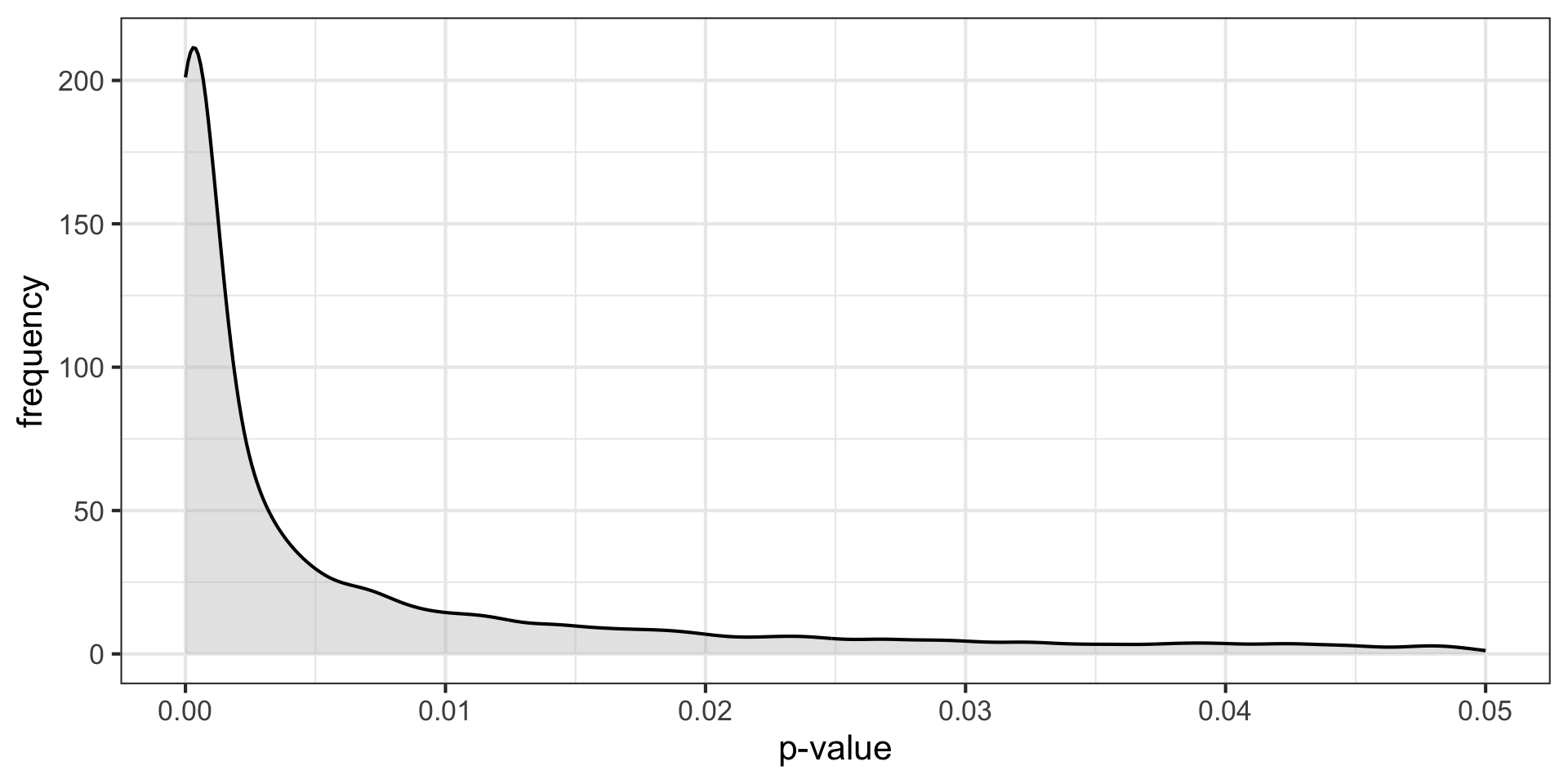
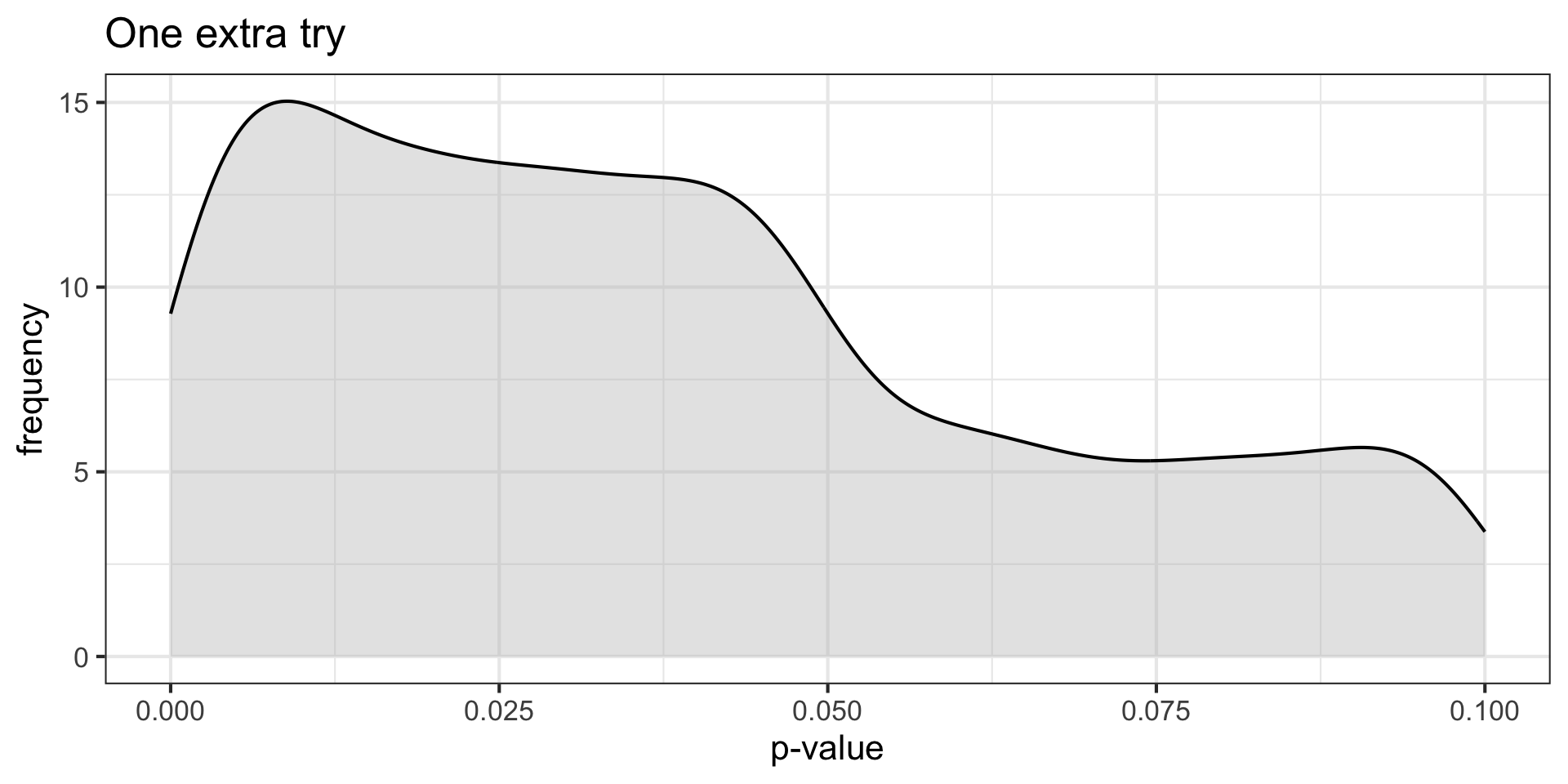
\(H_O\) true \((N = 30, \mu = 0, \sigma = 1)\) and non-independence
Code
set.seed(201112)
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
try = 1
sample_p = 1
# while these statements are true,
# keep going
while(sample_p >= .05 & try <= 2){
sample = rnorm(n = N,
mean = 0,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
try = try+1
}
p_values[i] = sample_p
}
\(H_O\) true \((N = 30, \mu = 0, \sigma = 1)\) and non-independence
Code
set.seed(201112)
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
try = 1
sample_p = 1
# while these statements are true,
# keep going
while(sample_p >= .05 & try <= 3){
try = try+1
sample = rnorm(n = N,
mean = 0,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
}
p_values[i] = sample_p
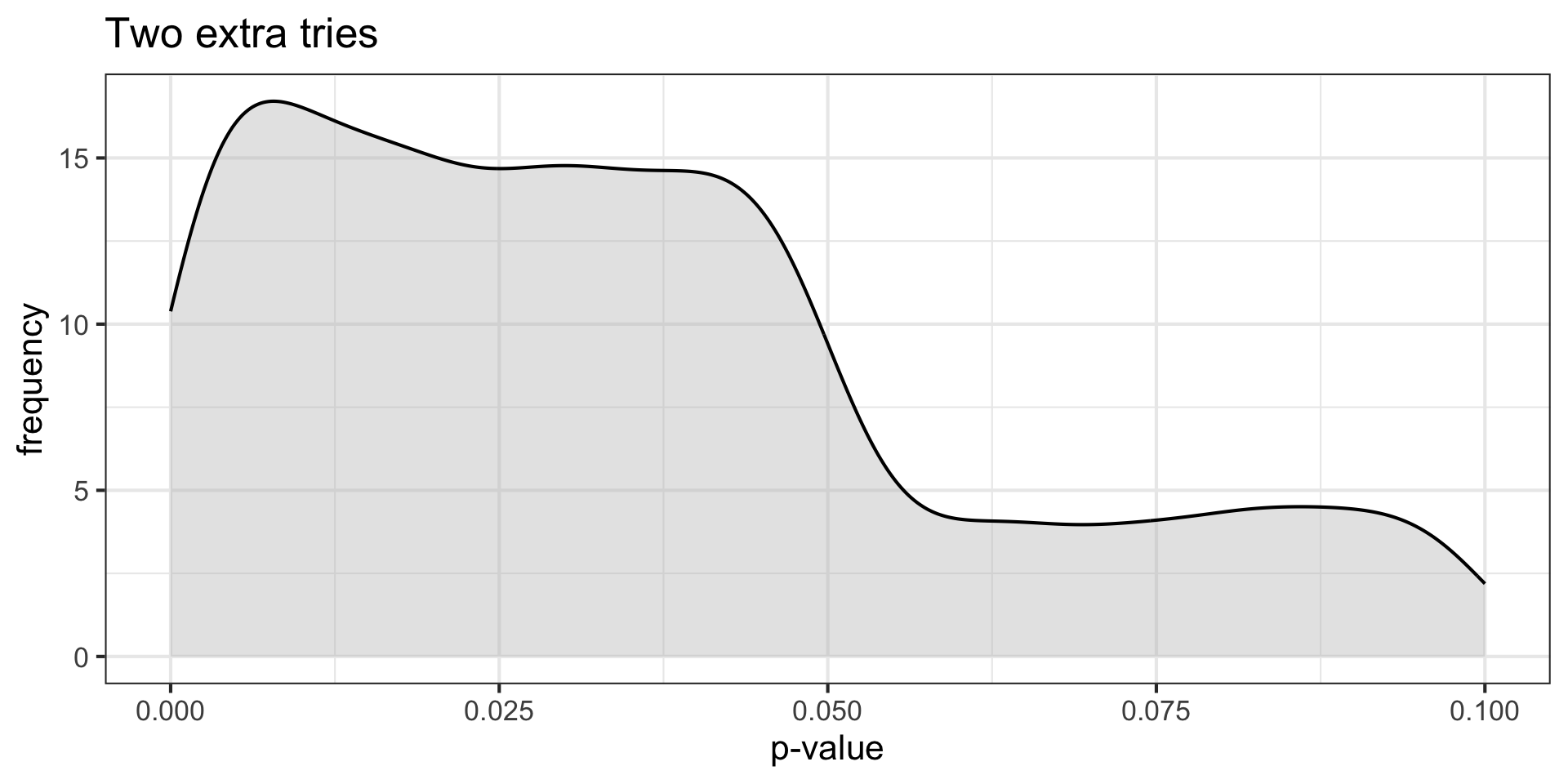
}
Code
phack_data = data.frame(sim = 1:sims, p=p_values,
type = "p-hack")
set.seed(201112)
# create empty vector for storing p-values
p_values = numeric(sims)
# loop
for(i in 1:sims){
# draw sample
sample = rnorm(n = N,
mean = .25,
sd = 1)
sample_mean = mean(sample)
sample_sd = sd(sample)
se_mean = sample_sd/sqrt(N)
z_stat = (sample_mean-0)/se_mean
sample_p = pnorm(q = abs(z_stat),
lower.tail = F)
p_values[i] = sample_p
}
nonp_data = data.frame(sim = 1:sims, p=p_values,
type = "true H1")
full_join(phack_data, nonp_data) %>%
ggplot(aes(x = p, fill = type)) +
geom_density(alpha = .4) +
scale_x_continuous(limits = c(0, .1)) +
theme_bw(base_size = 16) +
labs(x = "p-value", y = "frequency",
title = "Two extra tries")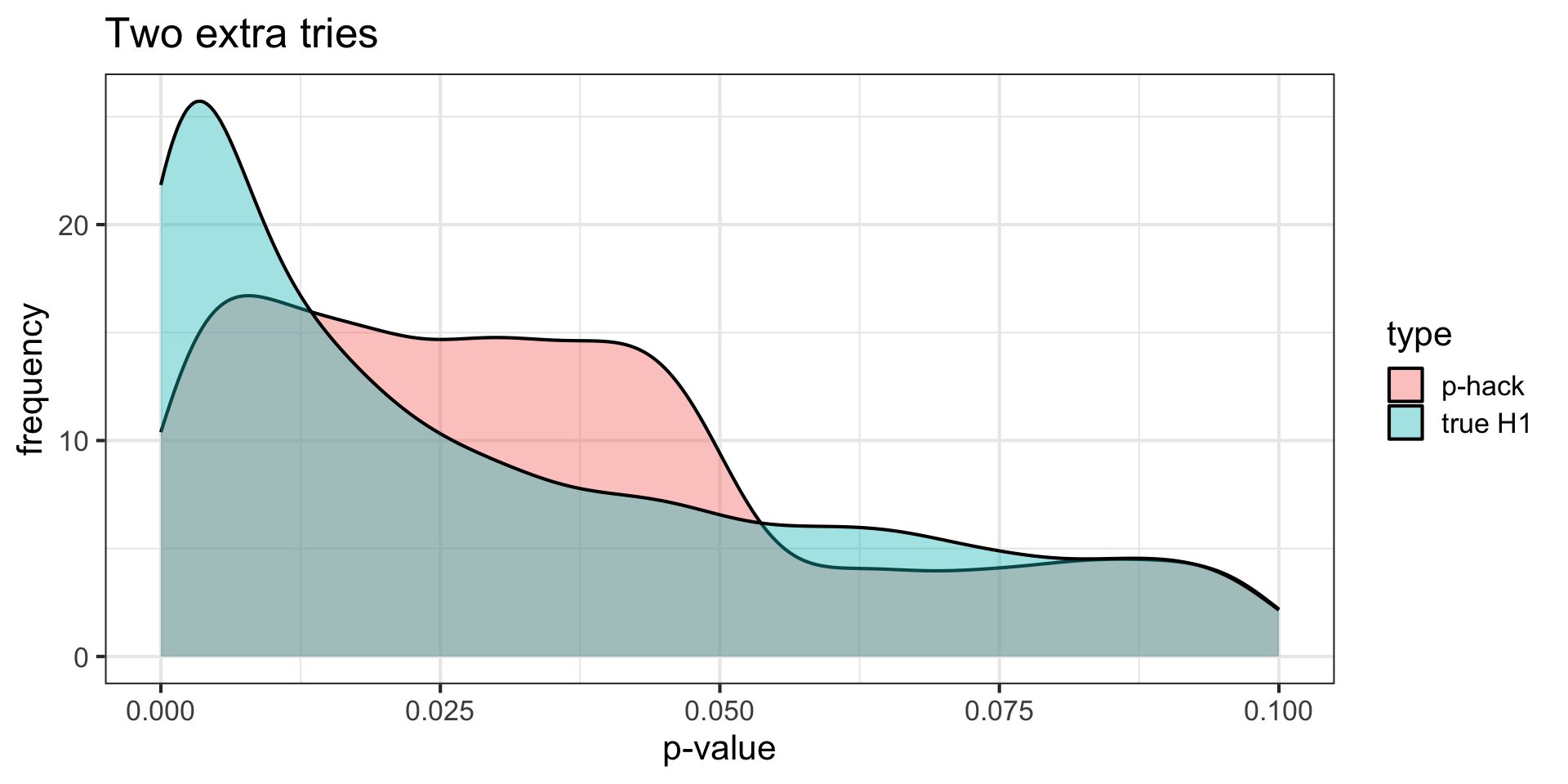
Only 36% of the studies were replicated, despite high power and claimed fidelity of the methods.
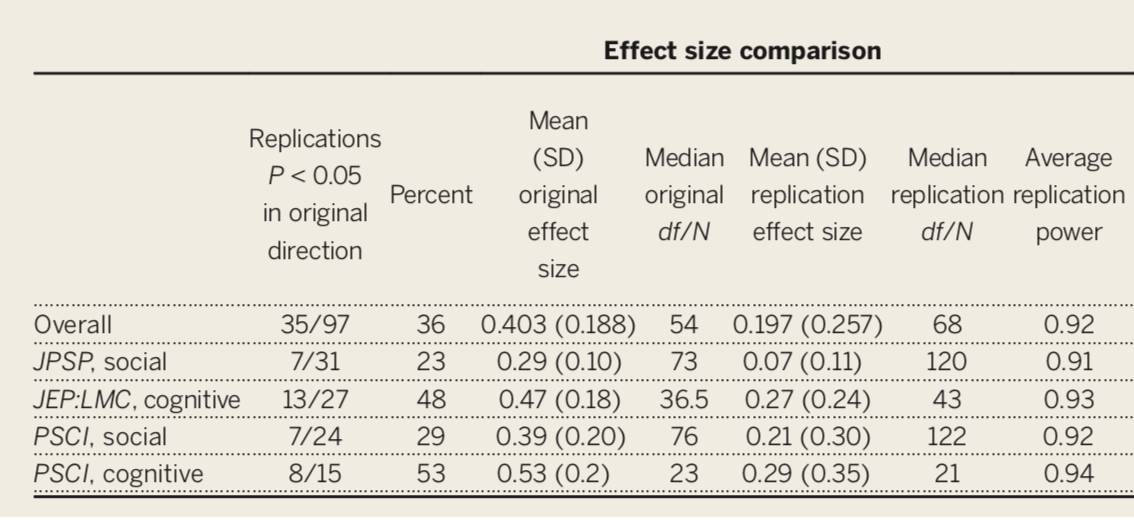
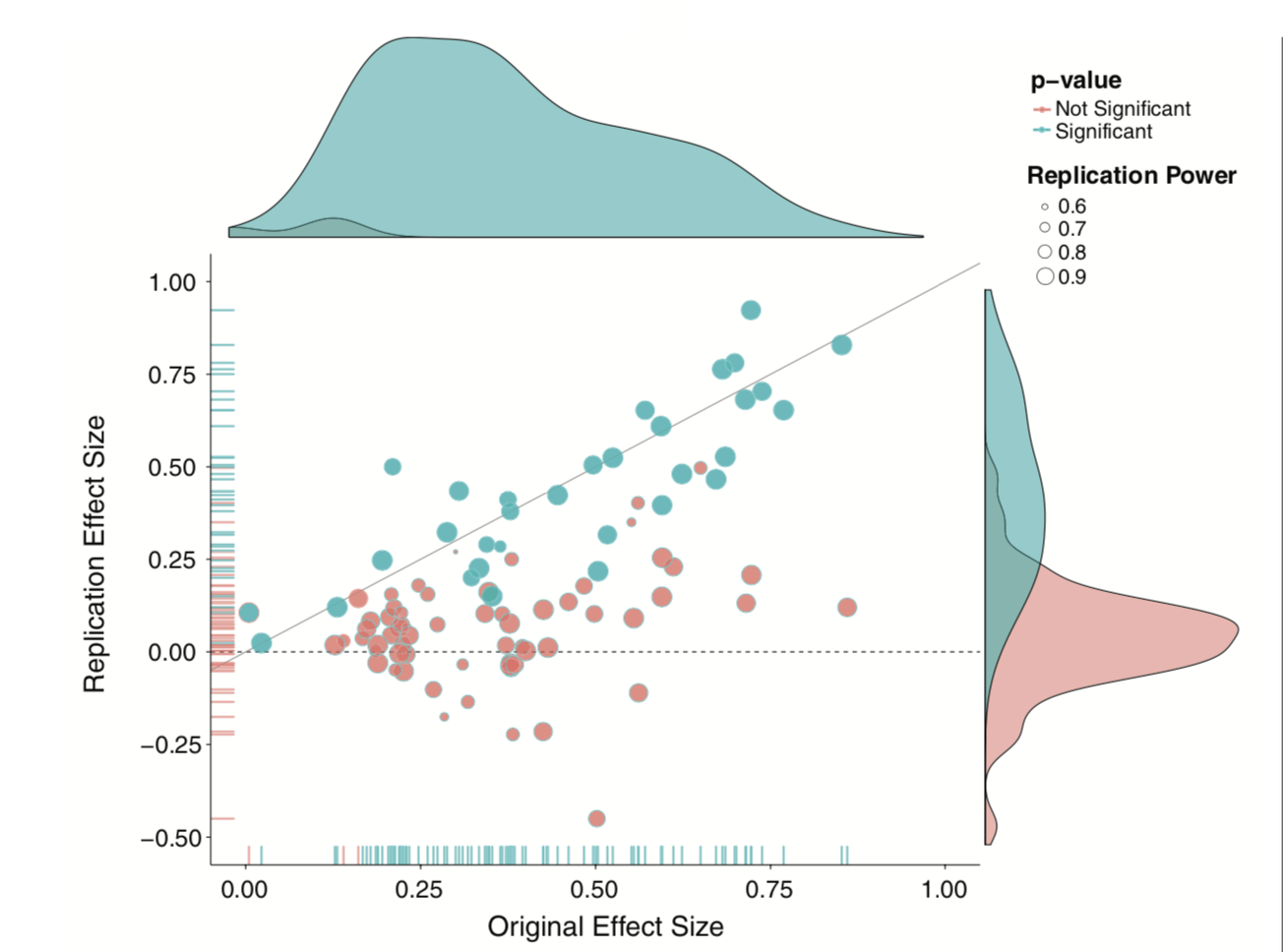
There is disagreement about what counts as “replicating the effect.” - Both studies significant? - Significant difference in effect size?
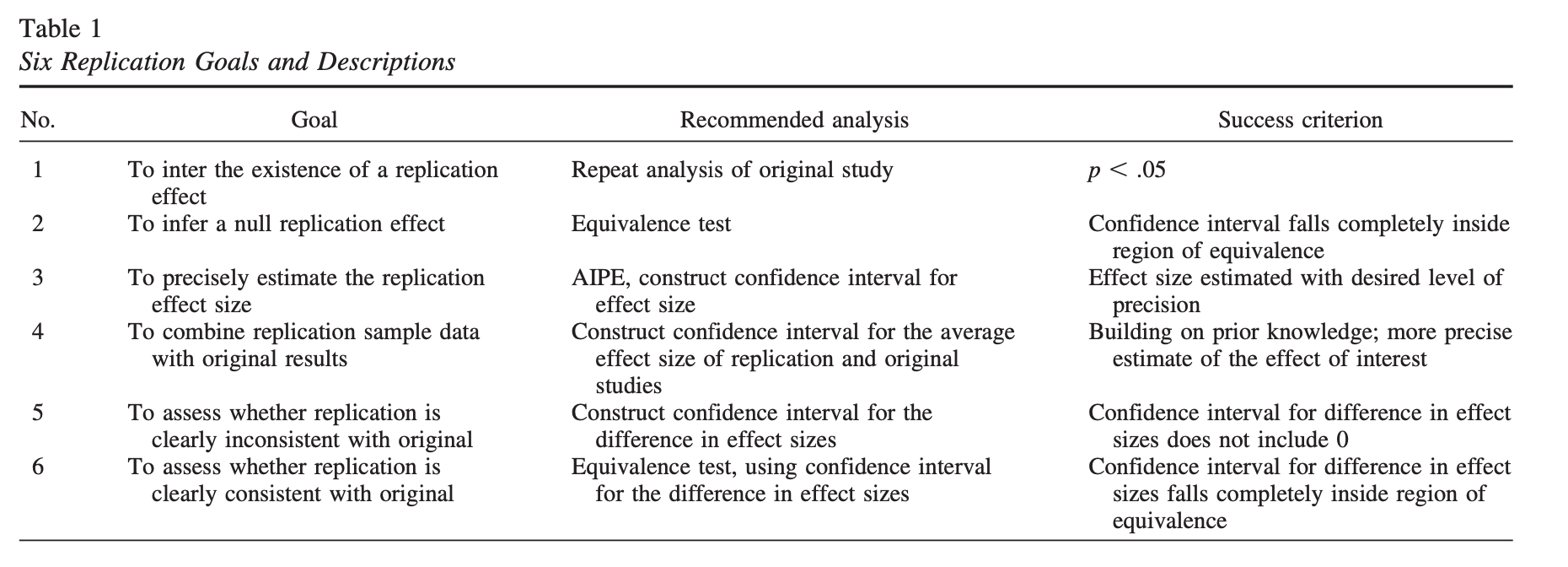
Anderson & Maxwell (2016)