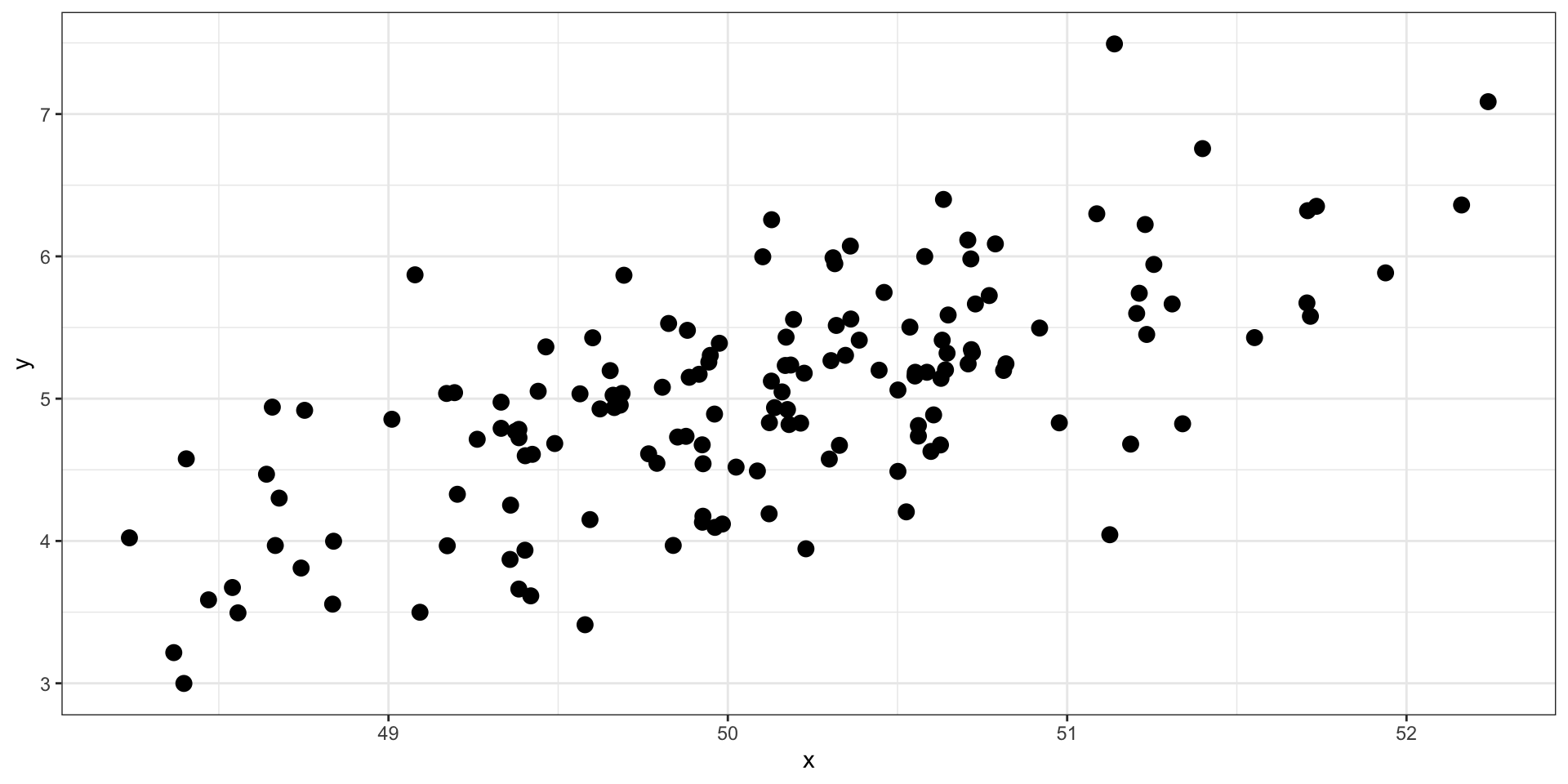
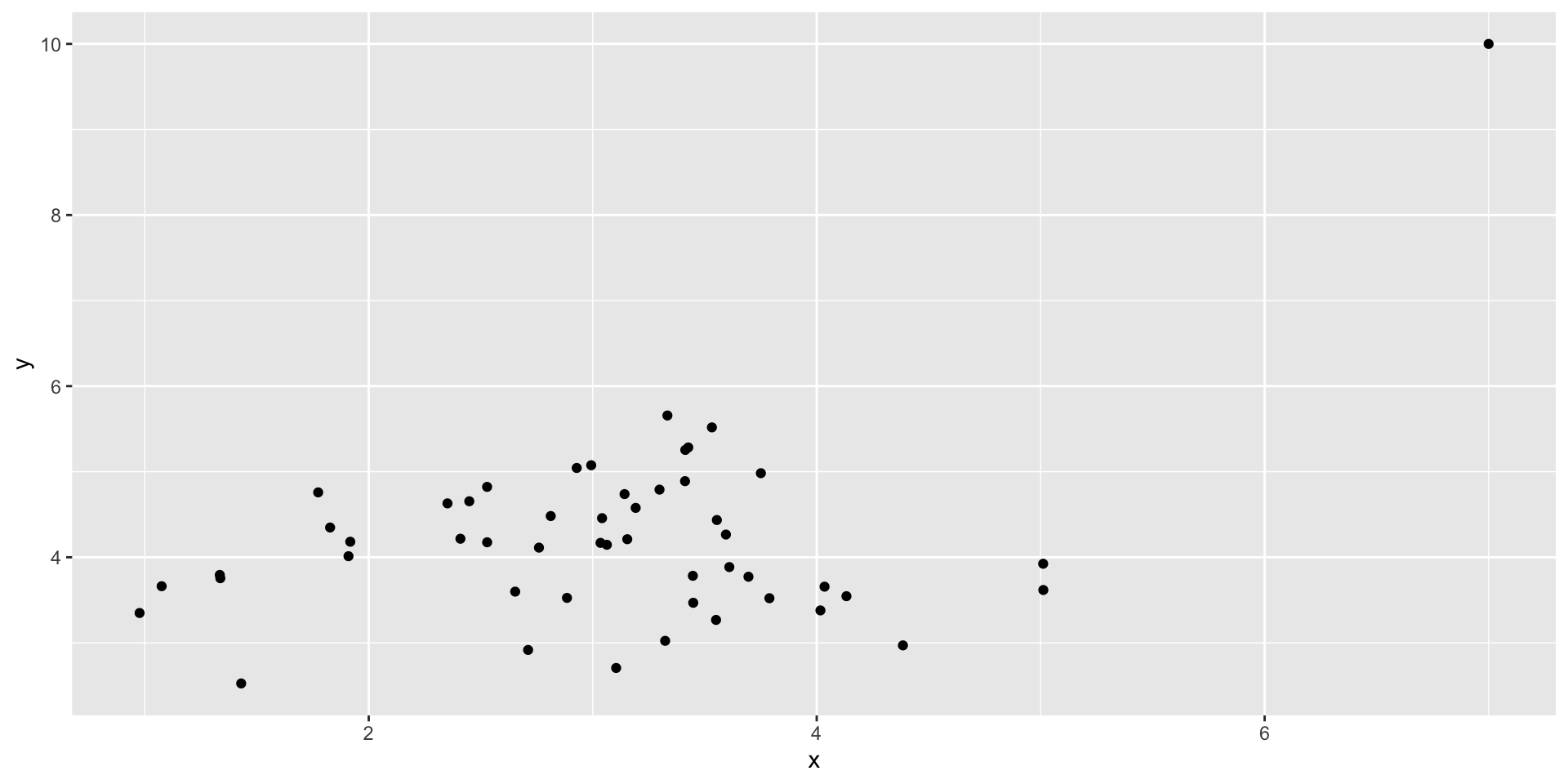
set.seed(101019) # so we all get the same random numbersmu =c(50, 5) # means of two variables (MX = 50, MY = 5)Sigma =matrix(c(.8, .5, .5, .7), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =150, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data %>%ggplot(aes(x = x, y = y)) +geom_point(size =3) +theme_bw()
What is the correlation between these two variables?
Code
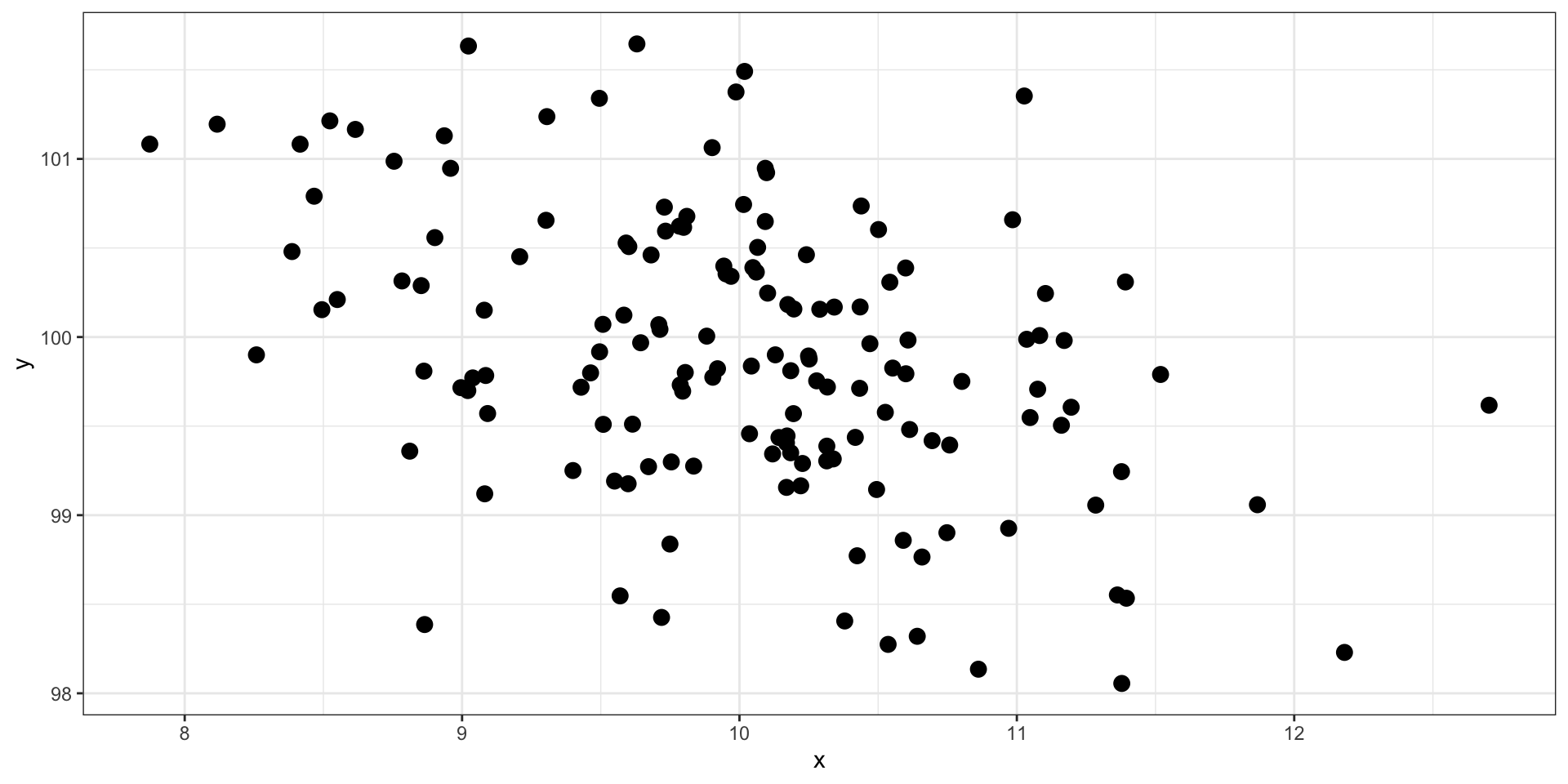
set.seed(101019) # so we all get the same random numbersmu =c(10, 100)Sigma =matrix(c(.8, -.3, -.3, .7), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =150, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data %>%ggplot(aes(x = x, y = y)) +geom_point(size =3) +theme_bw()
What is the correlation between these two variables?
Code
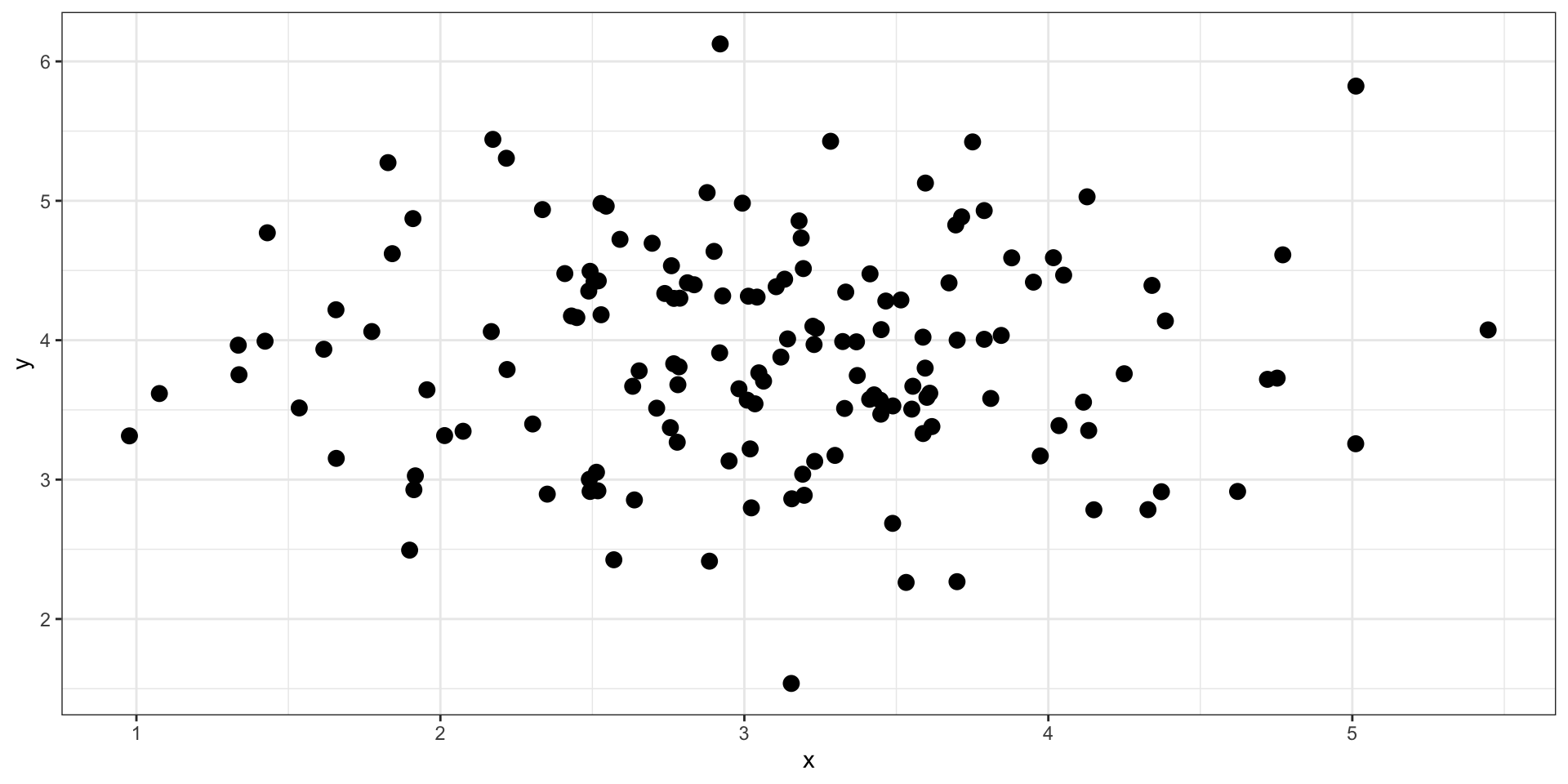
set.seed(101019) # so we all get the same random numbersmu =c(3, 4)Sigma =matrix(c(.8, 0, 0, .7), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =150, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data %>%ggplot(aes(x = x, y = y)) +geom_point(size =3) +theme_bw()
What is the correlation between these two variables?
Effect size
Recall that z-scores allow us to compare across units of measure; the products of standardized scores are themselves standardized.
The correlation coefficient is a standardized effect size which can be used communicate the strength of a relationship.
Correlations can be compared across studies, measures, constructs, time.
Example: the correlation between age and height among children is \(r = .70\). The correlation between self- and other-ratings of extraversion is \(r = .25\).
Fisher (2019) suggests this particular argument is non-scientific (follow up here and then here)
Funder & Ozer (2019)
Effect sizes are often mis-interpreted. How?
What can fix this?
Pitfalls of small effects and large effects
Recommendations?
What affects correlations?
It’s not enough to calculate a correlation between two variables. You should always look at a figure of the data to make sure the number accurately describes the relationship. Correlations can be easily fooled by qualities of your data, like:
Skewed distributions
Outliers
Restriction of range
Nonlinearity
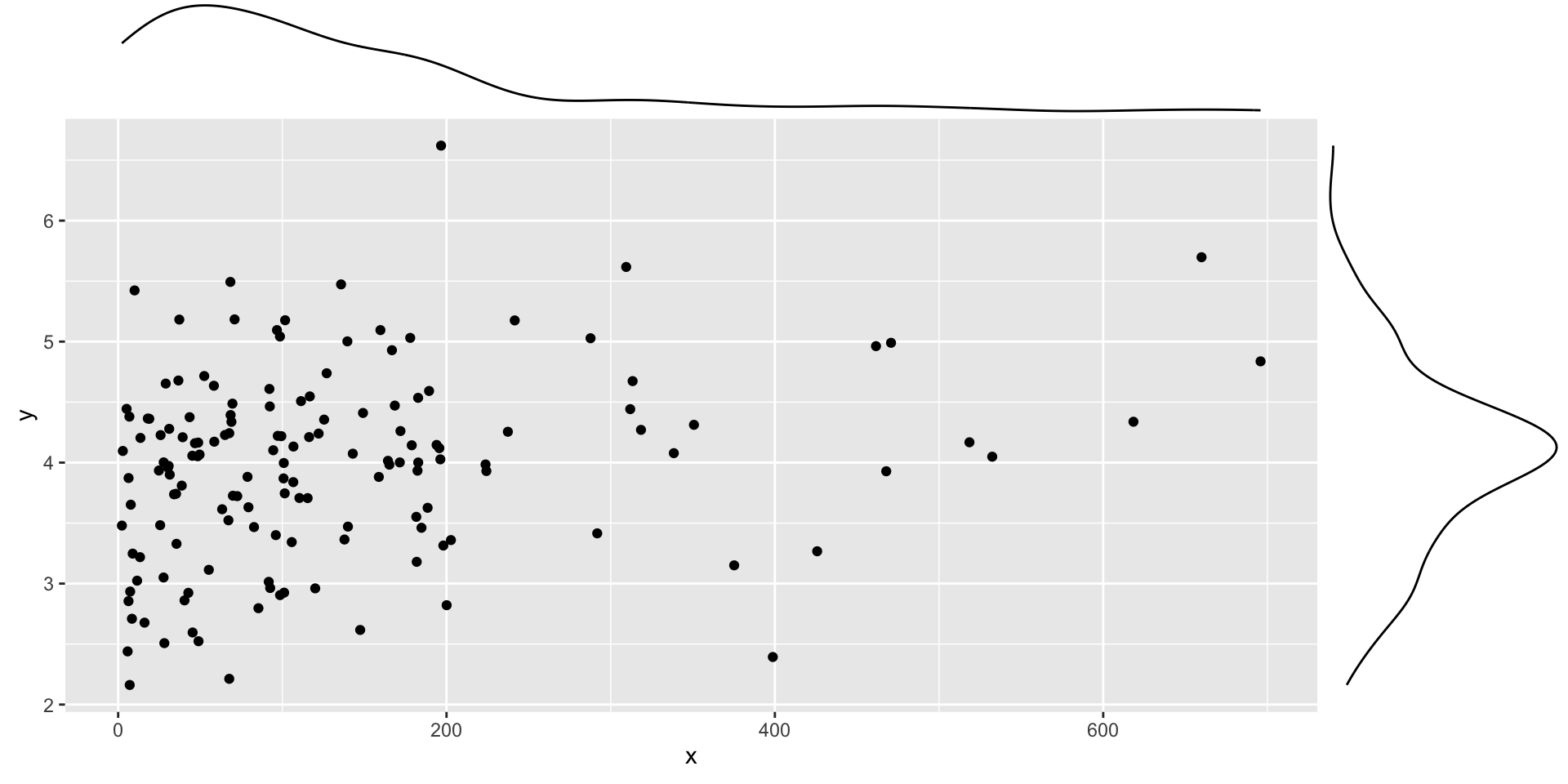
Skewed distributions
Code
set.seed(101019) # so we all get the same random numbersmu =c(3, 4)Sigma =matrix(c(.8, .2, .2, .7), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =150, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data$x = data$x^4p = data %>%ggplot(aes(x=x, y=y)) +geom_point()ggMarginal(p, type ="density")
Outliers
Code
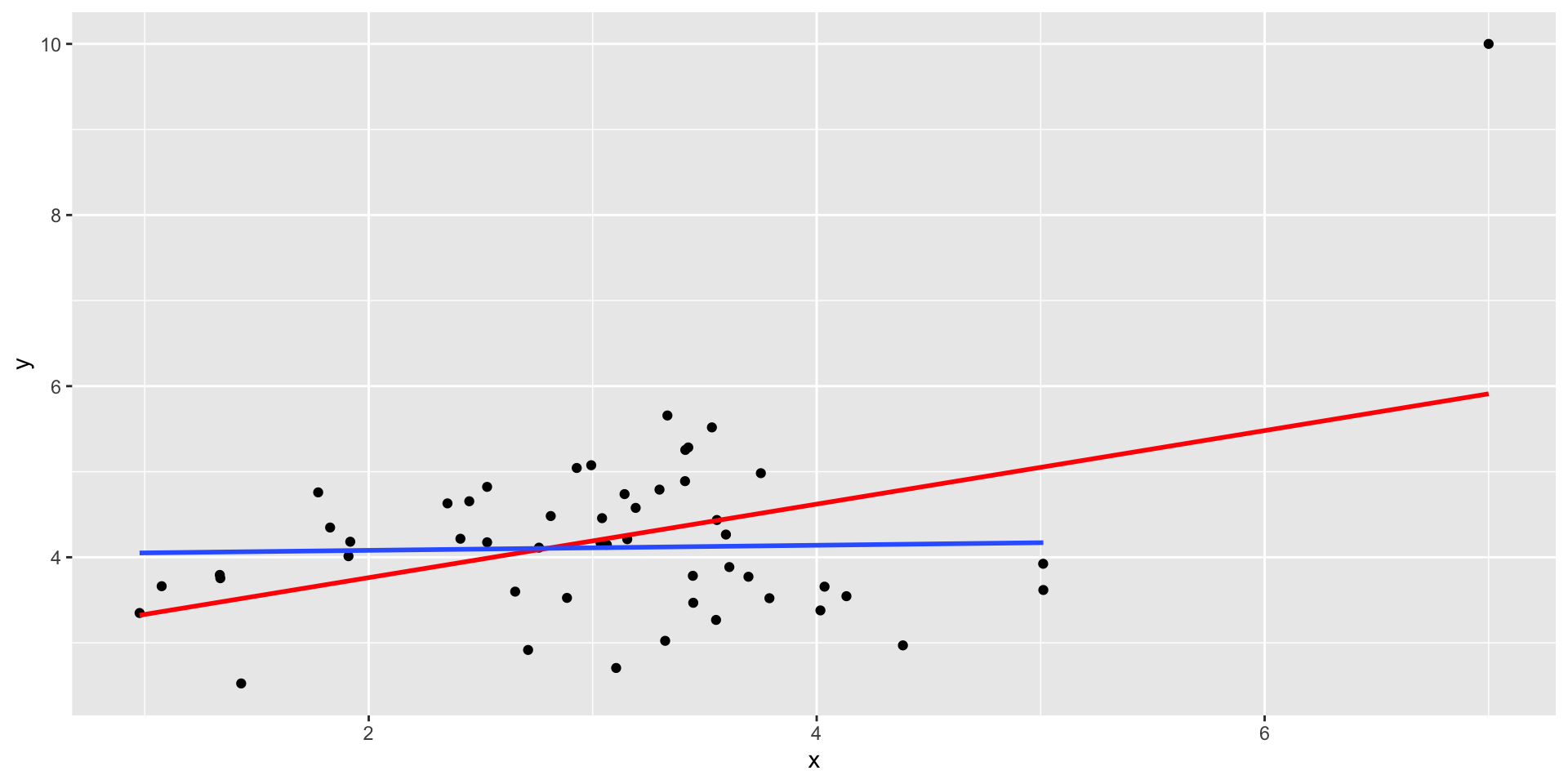
set.seed(101019) # so we all get the same random numbersmu =c(3, 4)Sigma =matrix(c(.8, 0, 0, .7), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =50, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data[51, ] =c(7, 10)data %>%ggplot(aes(x=x, y=y)) +geom_point()
Outliers
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red") +geom_smooth(data = data[-51,], method ="lm", se =FALSE)
Outliers
Code
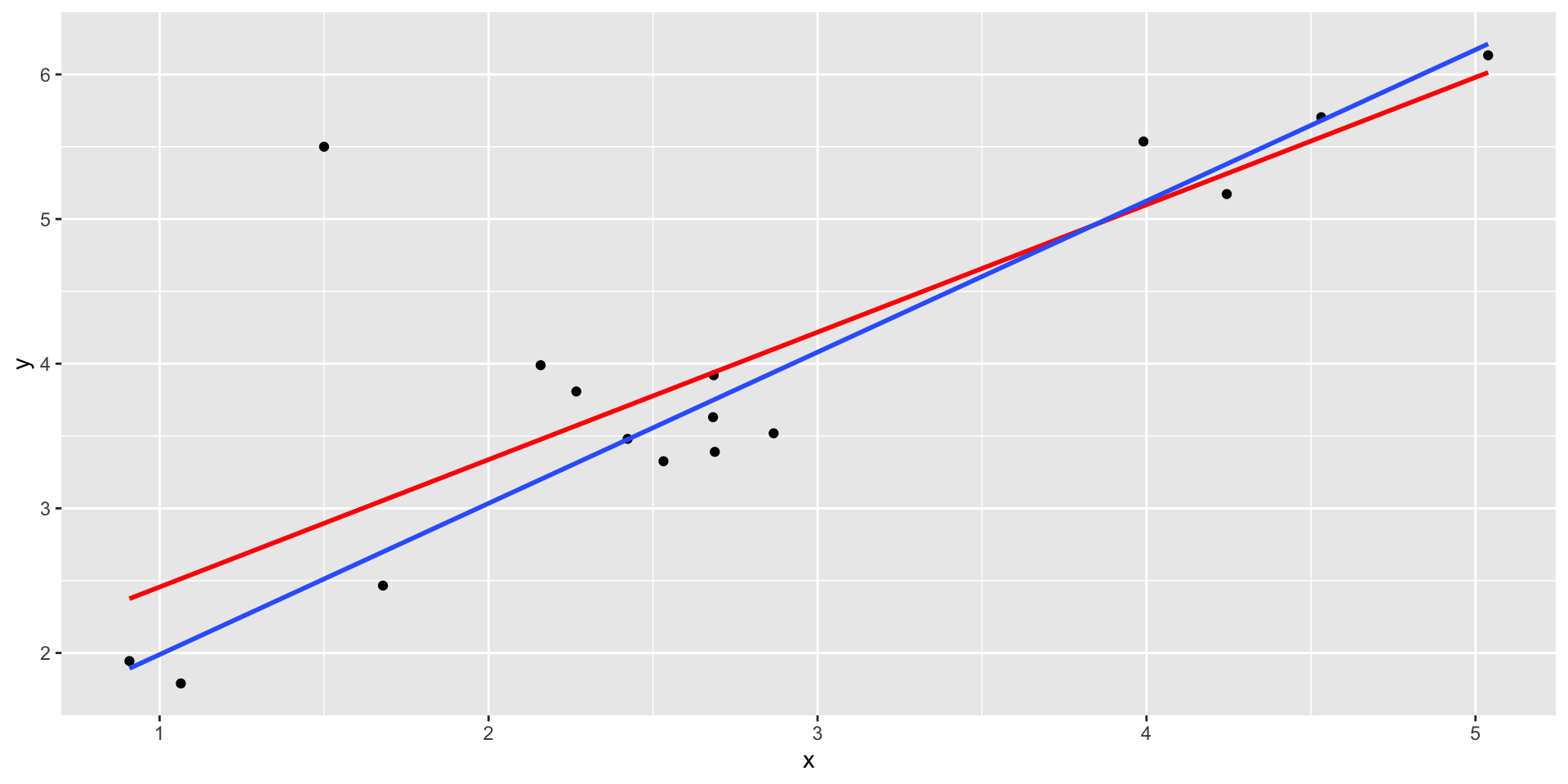
set.seed(101019) # so we all get the same random numbersmu =c(3, 4)n =15Sigma =matrix(c(.9, .8, .8, .9), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n = n, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")data[n+1, ] =c(1.5, 5.5)
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red") +geom_smooth(data = data[-c(n+1),], method ="lm", se =FALSE)
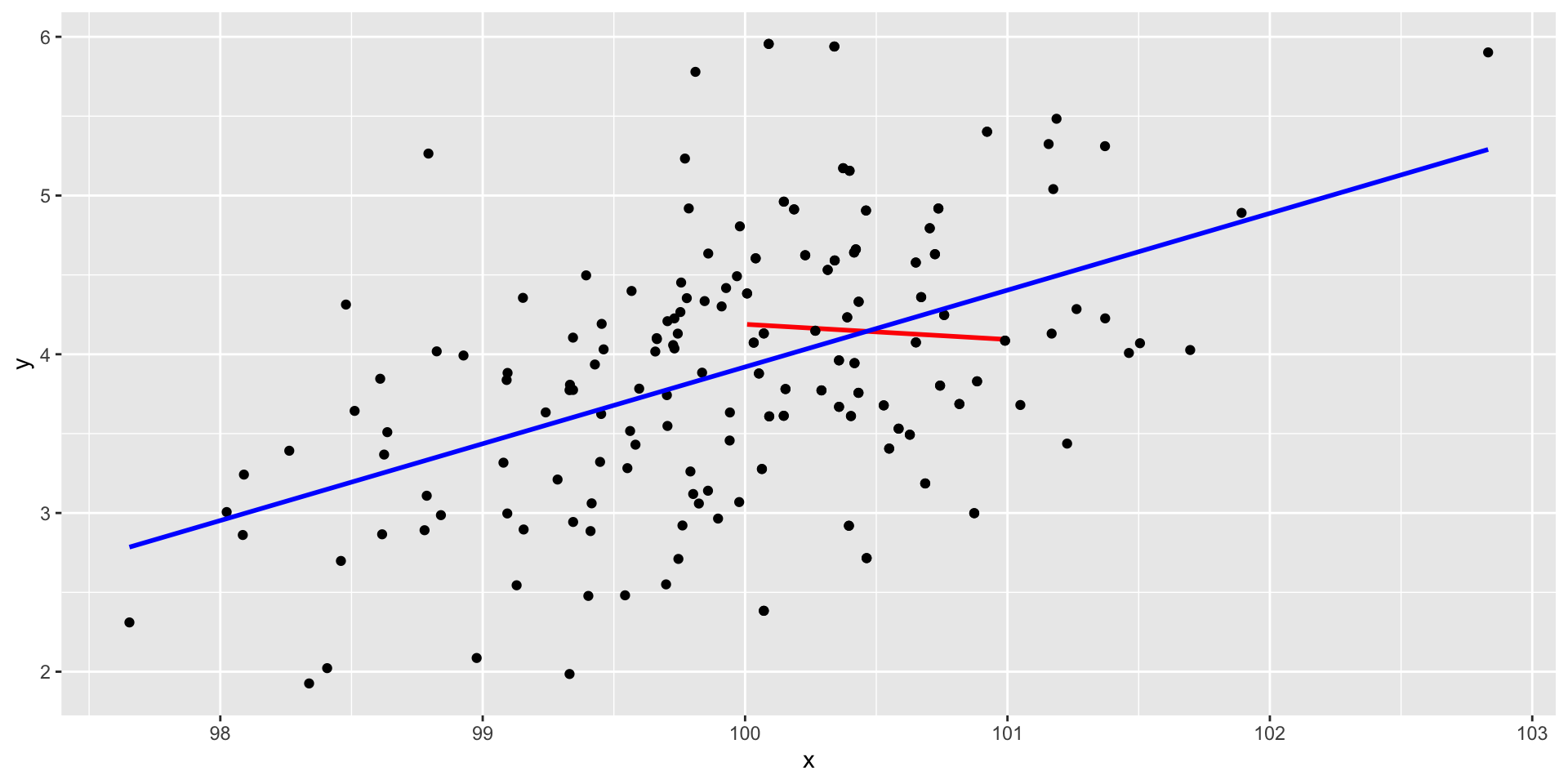
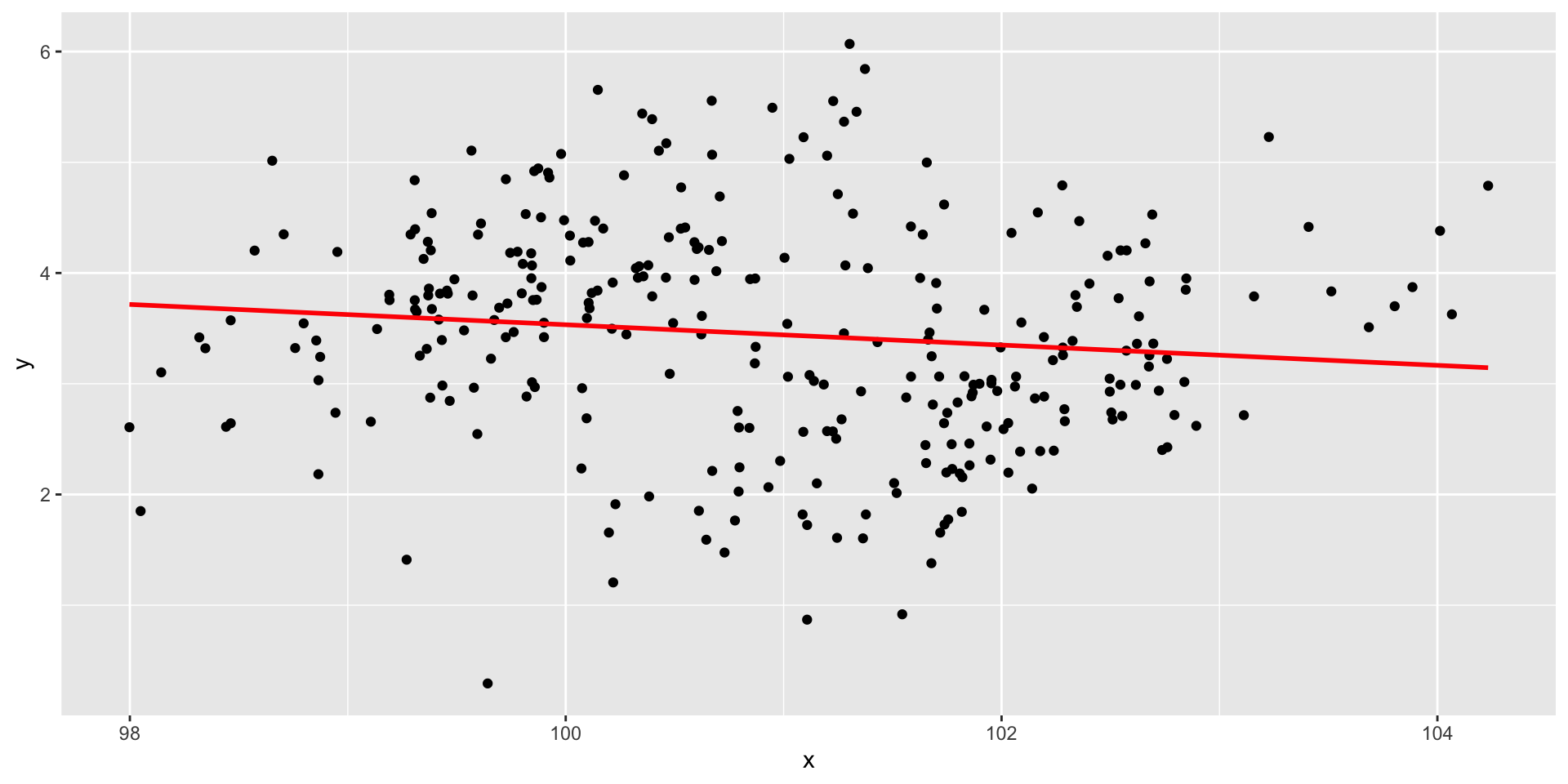
Restriction of range
Code
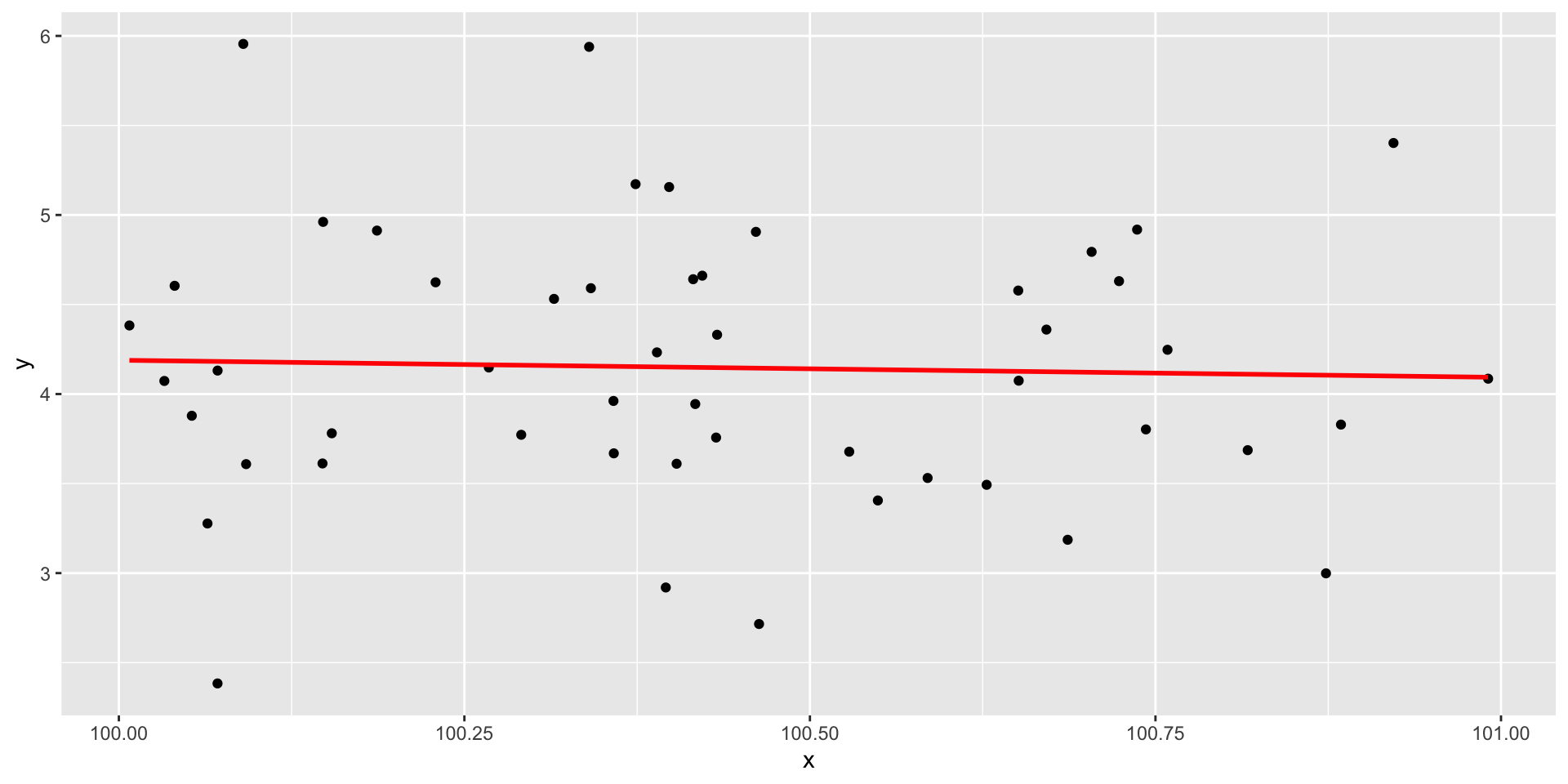
set.seed(1010191) # so we all get the same random numbersmu =c(100, 4)Sigma =matrix(c(.7, .4, 4, .75), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsdata =mvrnorm(n =150, mu = mu, Sigma = Sigma)data =as.data.frame(data)colnames(data) =c("x", "y")real_data = datadata =filter(data, x >100& x <101)
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red")
Restriction of range
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red") +geom_point(data = real_data) +geom_smooth(method ="lm", se =FALSE, data = real_data, color ="blue")
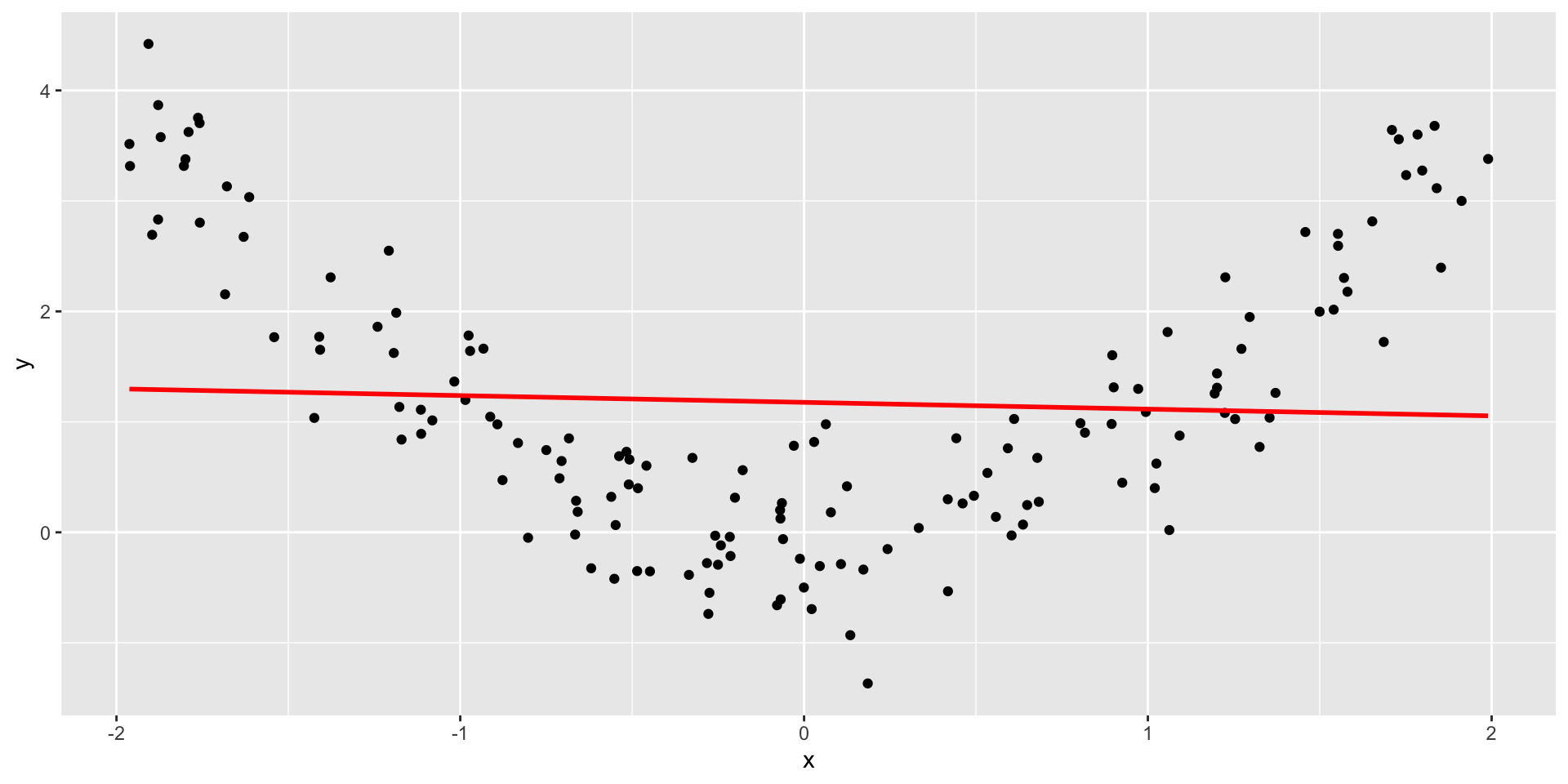
Nonlinearity
Code
x =runif(n =150, min =-2, max =2)y = x^2+rnorm(n =150, sd = .5)data =data.frame(x,y)
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red")
It’s not always apparent
Sometimes issues that affect correlations won’t appear in your graph, but you still need to know how to look for them.
Low reliability
Content overlap
Multiple groups
Reliability
\[r_{xy} = \rho_{xy}\sqrt{r_{xx}r_{yy}}\]
Meaning that our estimate of the population correlation coefficient is attenuated in proportion to reduction in reliability.
If you have a bad measure of X or Y, you should expect a lower estimate of\(\rho\).
Content overlap
If your Operation Y of Construct B includes items (or tasks or manipulations) that could also be influenced by Constrct A, then the correlation between X and Y will be inflated.
Example: SAT scores and IQ tests
Example: Depression and number of hours sleeping
Which kind of validity is this associated with?
In-class demo
Add your height (in inches), forearm length (in inches), and gender to this spreadsheet: tinyurl.com/uwn463vj
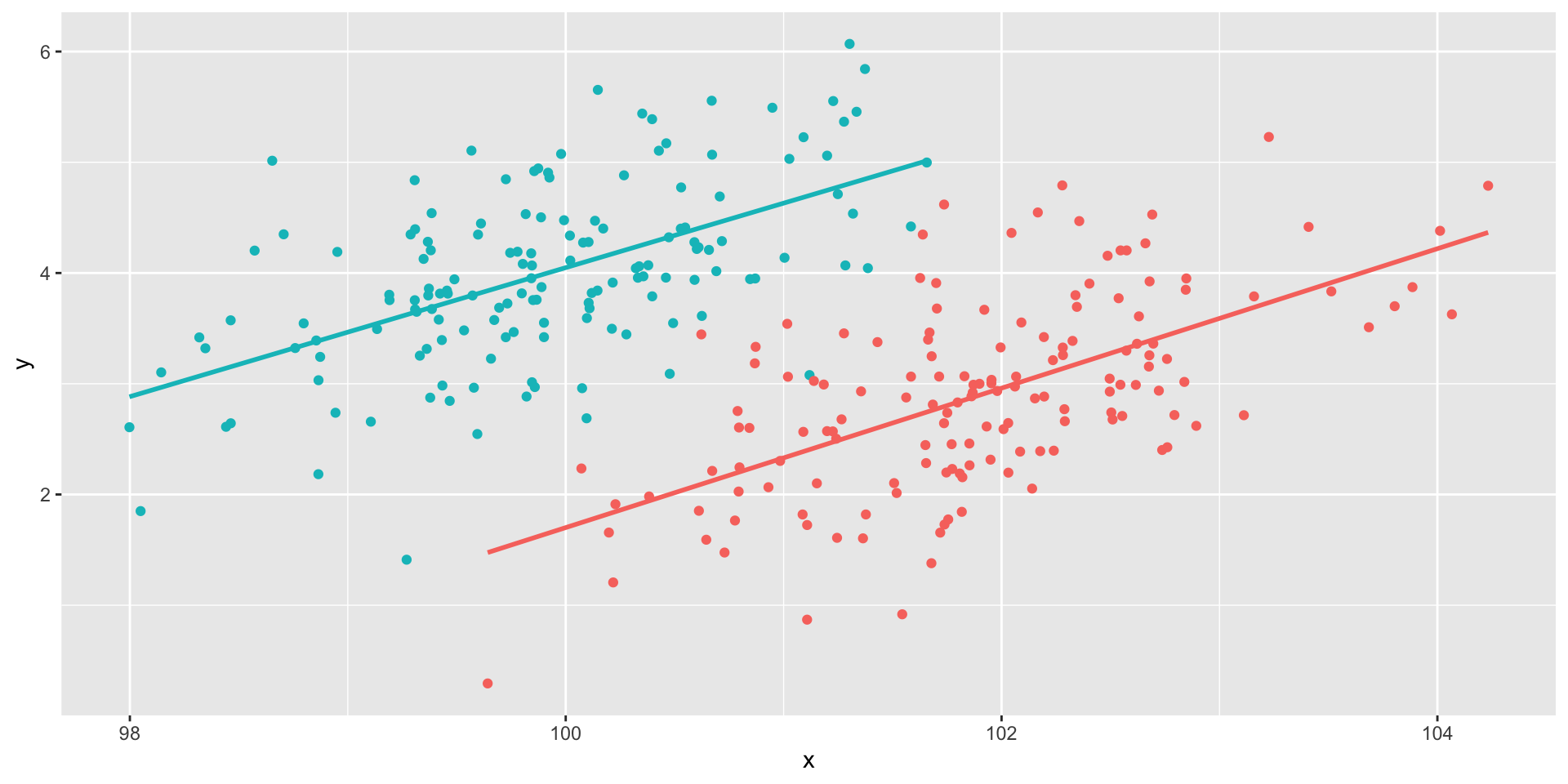
Multiple groups
Code
set.seed(101019) # so we all get the same random numbersm_mu =c(100, 4)m_Sigma =matrix(c(.7, .4, 4, .75), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsm_data =mvrnorm(n =150, mu = m_mu, Sigma = m_Sigma)m_data =as.data.frame(m_data)colnames(m_data) =c("x", "y")f_mu =c(102, 3)f_Sigma =matrix(c(.7, .4, 4, .75), ncol =2) #diagonals are reliabilites, off-diagonals are correlationsf_data =mvrnorm(n =150, mu = f_mu, Sigma = f_Sigma)f_data =as.data.frame(f_data)colnames(f_data) =c("x", "y")m_data$gender ="male"f_data$gender ="female"data =rbind(m_data, f_data)
data %>%ggplot(aes(x=x, y=y)) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="red")
Multiple groups
data %>%ggplot(aes(x=x, y=y, color = gender)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +guides(color ="none")
Special cases of the Pearson correlation
Spearman correlation coefficient
Applies when both X and Y are ranks (ordinal data) instead of continuous
Denoted \(\rho\) by your textbook, although I prefer to save Greek letters for population parameters.
Point-biserial correlation coefficient
Applies when Y is binary.
Phi (\(\phi\) ) coefficient
Both X and Y are dichotomous.
Do the special cases matter?
For Spearman, you’ll get a different answer.
x =rnorm(n =10); y =rnorm(n =10) #randomly generate 10 numbers from normal distribution
Here are two ways to analyze these data
head(cbind(x,y))
x y
[1,] -0.6682733 -0.3940594
[2,] -1.7517951 0.9581278
[3,] 0.6142317 0.8819954
[4,] -0.9365643 -1.7716136
[5,] -2.1505726 -1.4557637
[6,] -0.3593537 -1.2175787