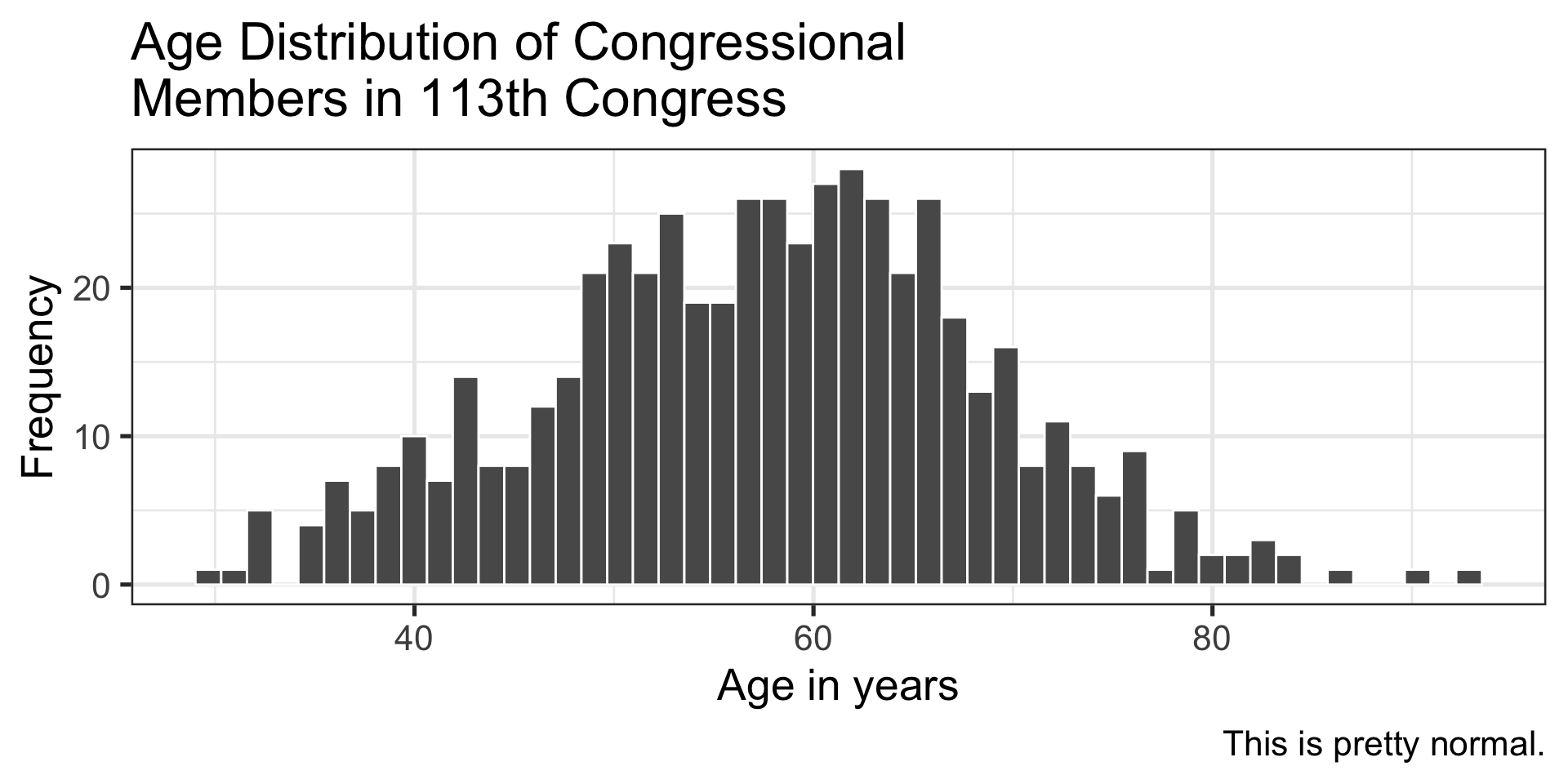
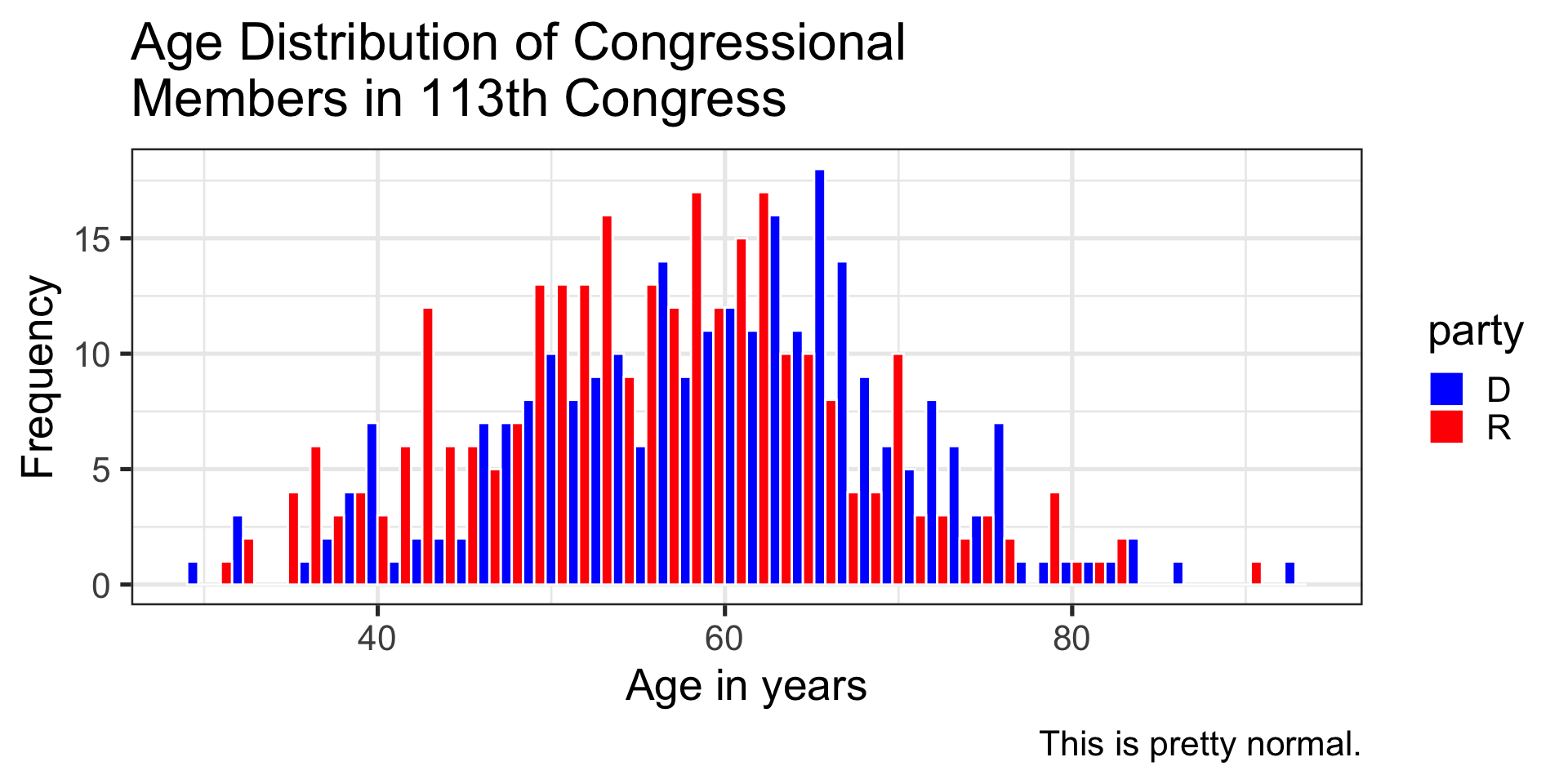
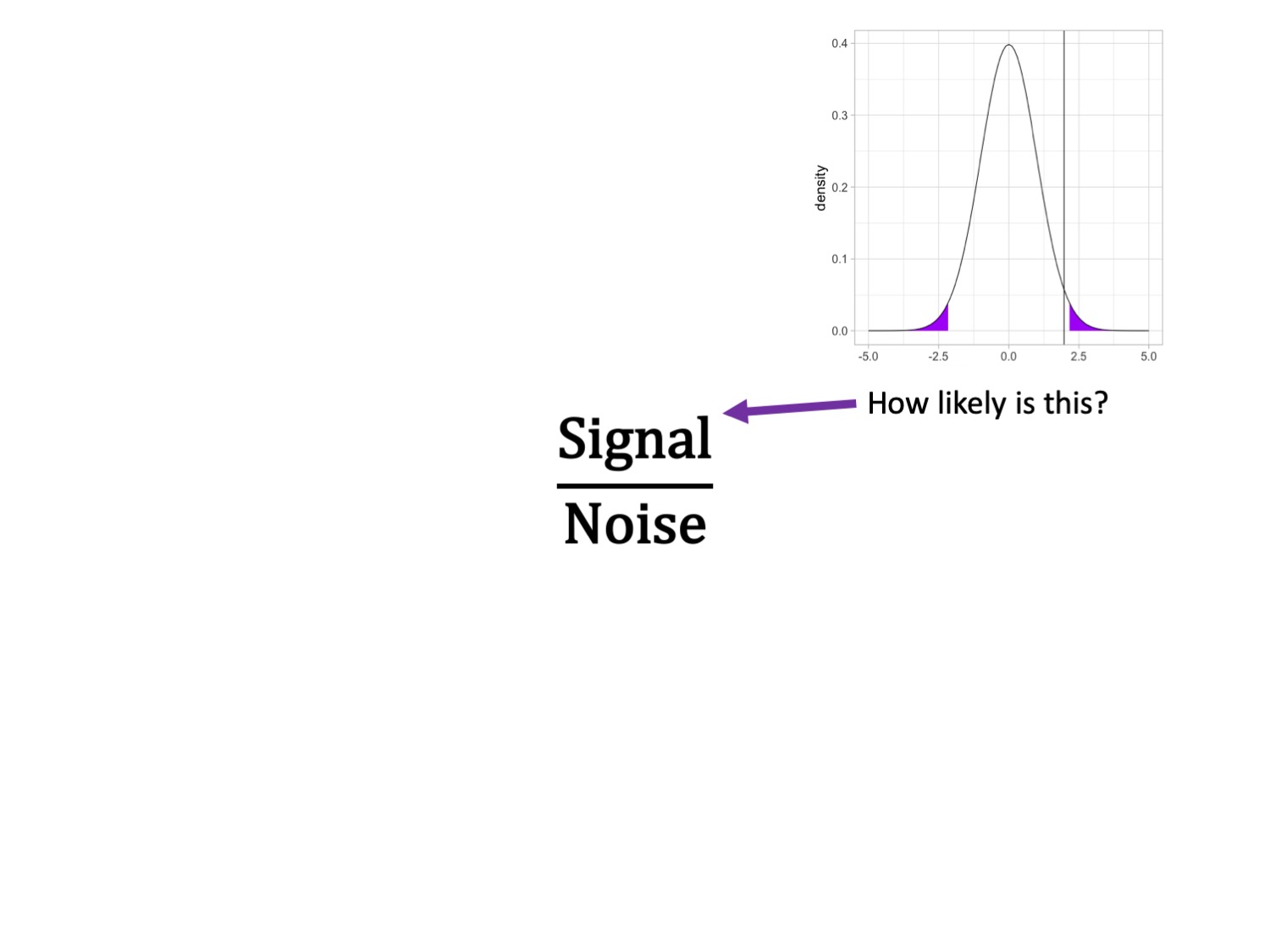
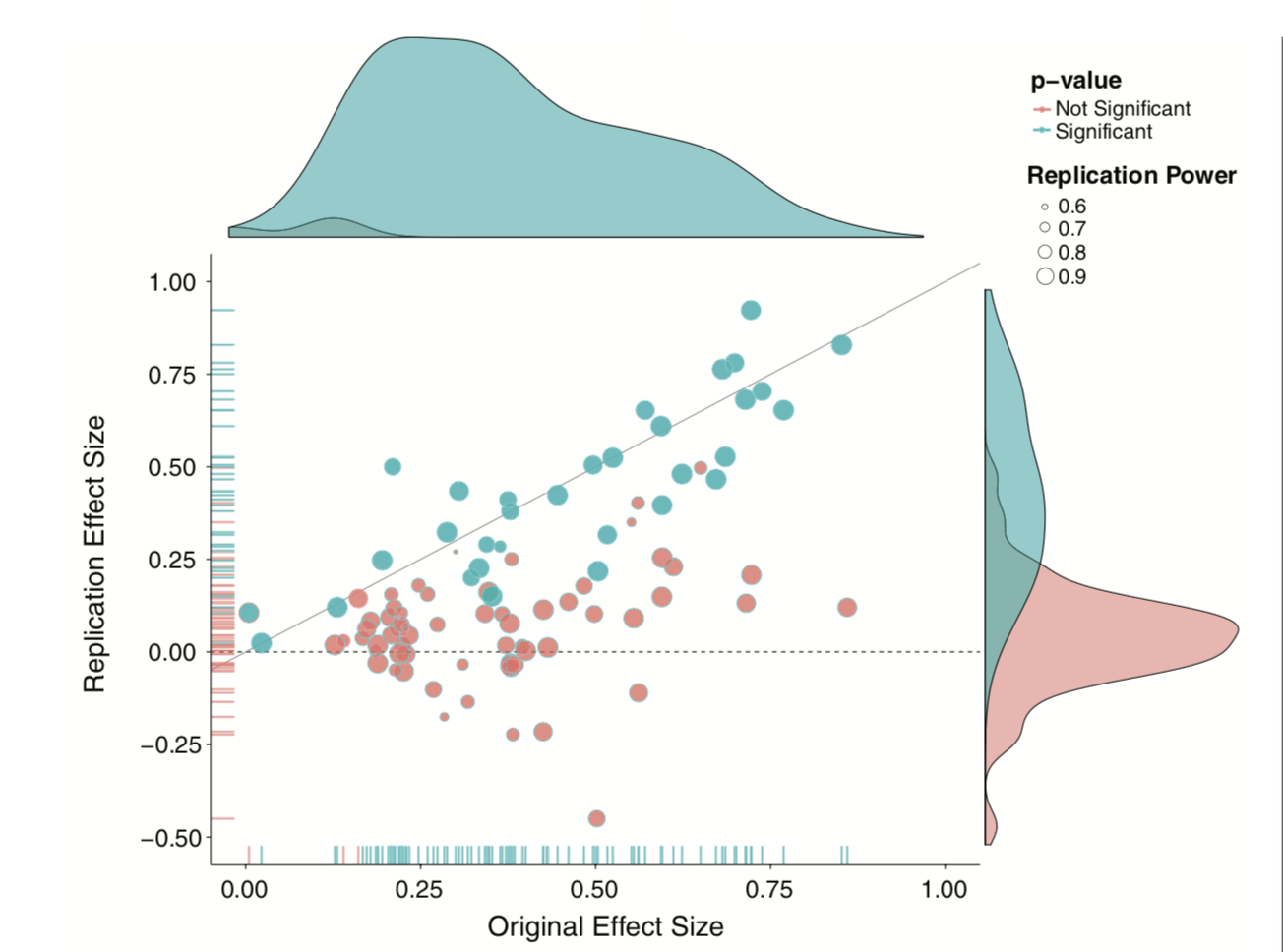
It’s generally argued that Republicans have an age problem – but are they substantially older than Democrats?
In 2014 (midterm election before the most recent presidential election), Five Thirty Eight did an analysis of the ages of elected members of Congress. They’ve provided their data, so we can run analyses on our own.
congress = congress_age %>%filter(congress ==113) %>%# just the most recentfilter(party %in%c("R", "D")) # remove independents
Code
congress %>%ggplot(aes(x = age)) +geom_histogram(bins =50, color ="white") +labs(x ="Age in years", y ="Frequency", title ="Age Distribution of Congressional \nMembers in 113th Congress", caption ="This is pretty normal.") +theme_bw(base_size =20)
Code
congress %>%ggplot(aes(x = age, fill = party)) +geom_histogram(bins =50, color ="white", position ="dodge") +labs(x ="Age in years", y ="Frequency", title ="Age Distribution of Congressional \nMembers in 113th Congress", caption ="This is pretty normal.") +scale_fill_manual(values =c("blue", "red")) +theme_bw(base_size =20)
psych::describeBy(congress$age, group = congress$party, fast = T)
Descriptive statistics by group
group: D
vars n mean sd min max range se
X1 1 259 59.55 10.85 29.8 93 63.2 0.67
------------------------------------------------------------
group: R
vars n mean sd min max range se
X1 1 283 55.78 10.68 31.6 89.7 58.1 0.64
\[ \bar{X}_1 = 59.55 \]
\[ \hat{\sigma}_1 = 10.85 \]
\[ N_1 = 259 \]
\[ \bar{X}_2 = 55.78 \]
\[ \hat{\sigma}_2 = 10.68 \]
\[ N_2 = 283 \]
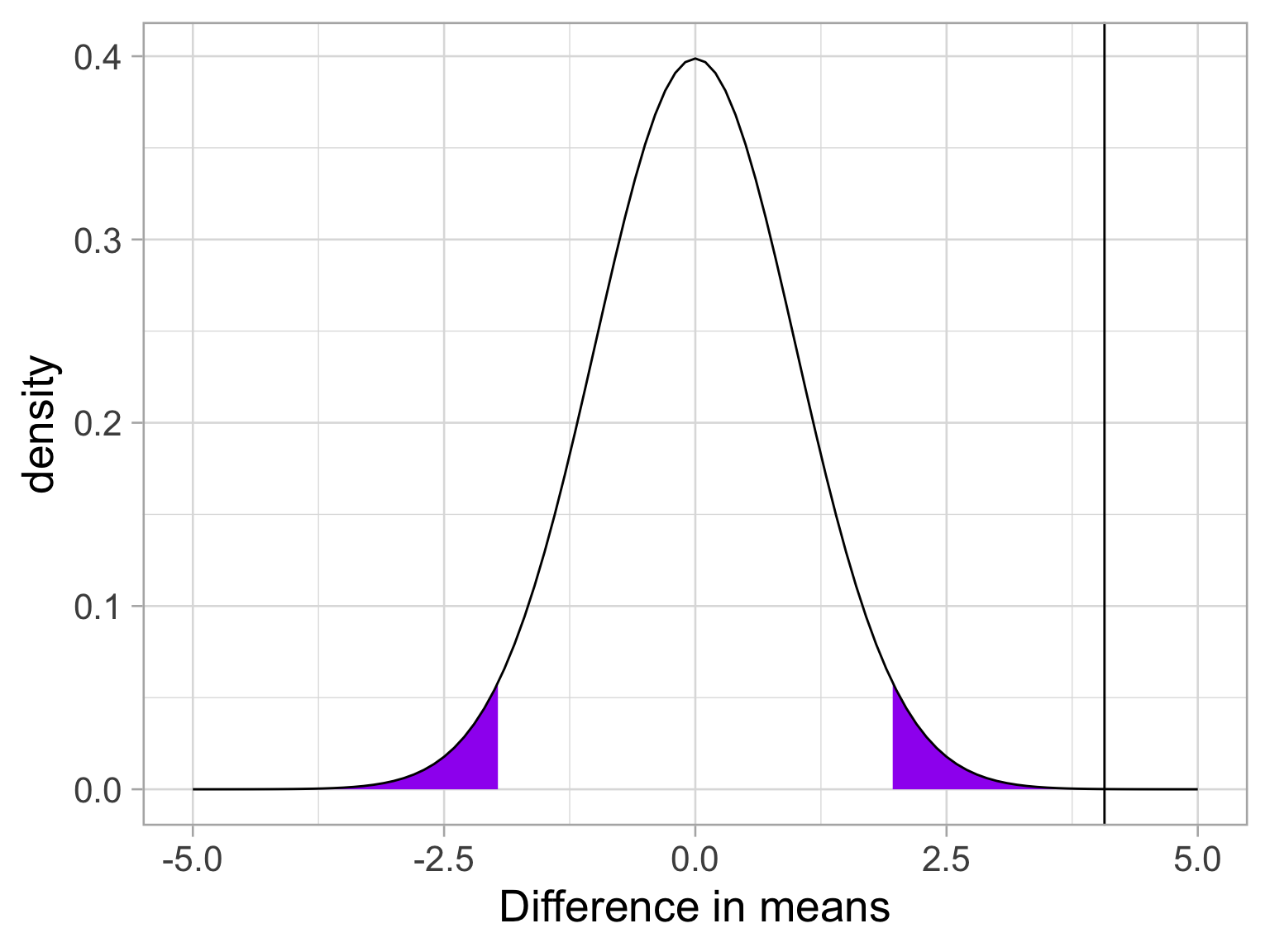
Next we build the sampling distribution under the null hypotheses.
x =c(-5:5)data.frame(x) %>%ggplot(aes(x=x)) +stat_function(fun=function(x) dt(x, df = df), geom ="area", xlim =c(cv, 5), fill ="purple") +stat_function(fun=function(x) dt(x, df = df), geom ="area", xlim =c(-5, cv*-1), fill ="purple") +stat_function(fun=function(x) dt(x, df = df), geom ="line") +geom_vline(aes(xintercept = t), color ="black")+labs(x ="Difference in means", y ="density") +theme_light(base_size =20)
Code
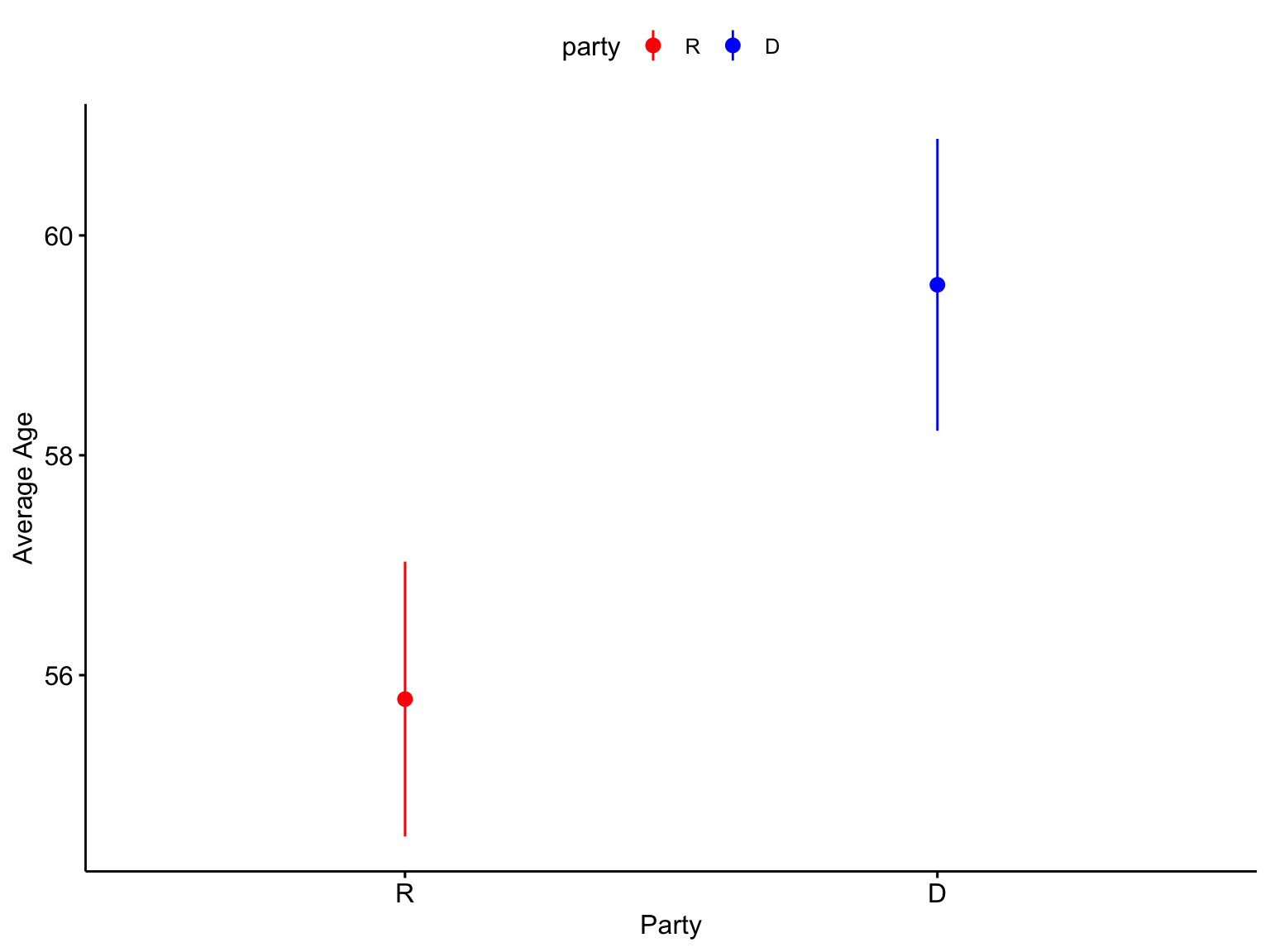
ggerrorplot(congress, x ="party", y ="age", desc_stat ="mean_ci", xlab ="Party", ylab ="Average Age", color ="party", palette =c("red", "blue"))
Code
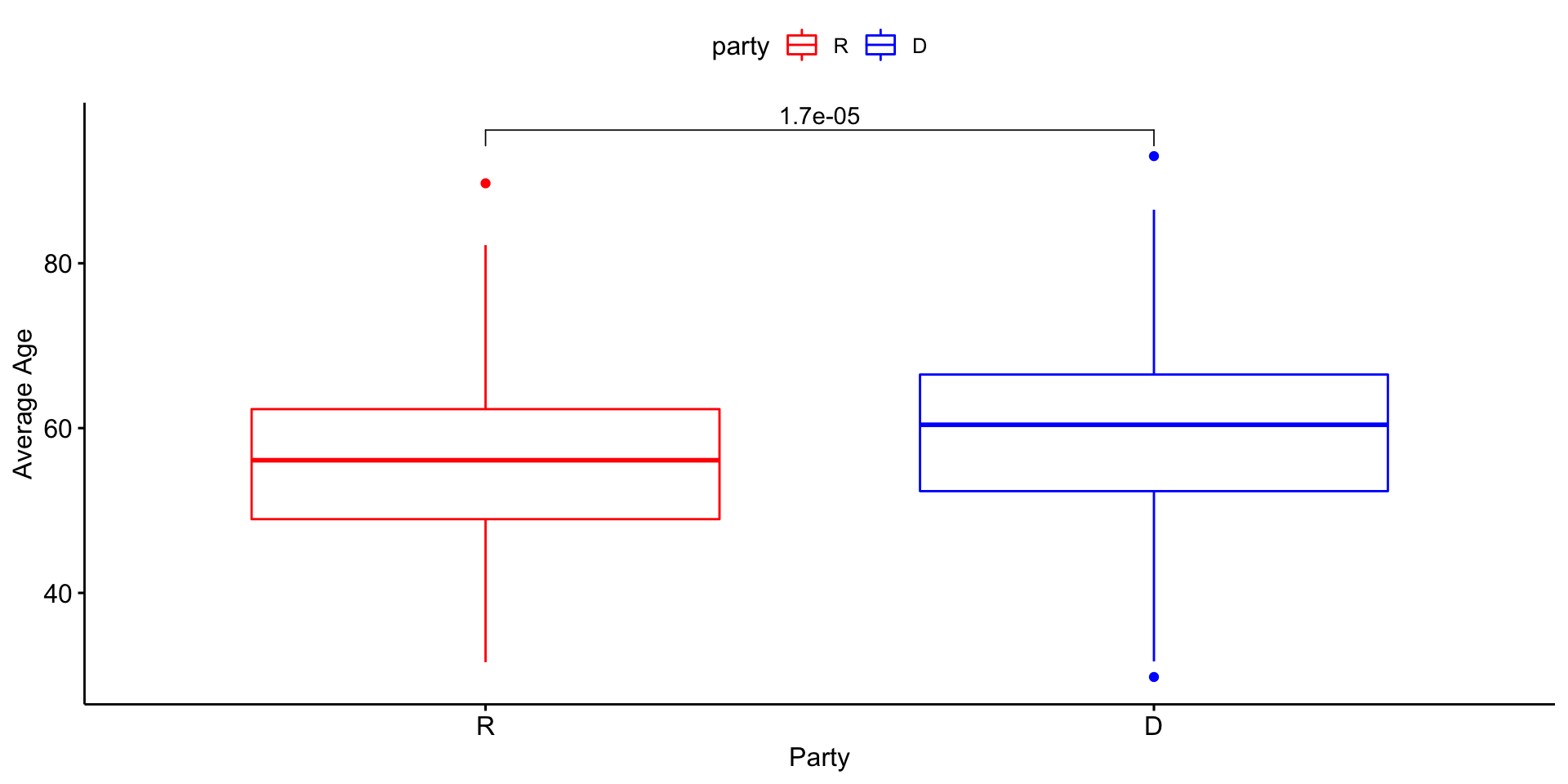
ggboxplot(congress, x ="party", y ="age",xlab ="Party", ylab ="Average Age", color ="party", palette =c("red", "blue"))+stat_compare_means(comparisons =list(c("R", "D")))
Effect sizes
Cohen suggested one of the most common effect size estimates—the standardized mean difference—useful when comparing a group mean to a population mean or two group means to each other. This is referred to as Cohen’s d.
\[\delta = \frac{\mu_1 - \mu_0}{\sigma} \approx d = \frac{\bar{X}_1-\bar{X}_2}{\hat{\sigma}_p}\]
Cohen’s d is in the standard deviation (Z) metric.
What happens to Cohen’s d as sample size gets larger?
Cohen1 suggests the following guidelines for interpreting the size of d:
.2 = Small
.5 = Medium
.8 = Large
An aside, to calculate Cohen’s D for a one-sample t-test:
\[d = \frac{\bar{X}-\mu}{\hat{\sigma}}\]
Cohen’s D (Paired-samples t)
Recall our gull example from the paired-samples t-test lecture. The average difference in seconds was \(83.11 (SD = 115.85)\).
t.test(gulls$At, gulls$Away, paired = T)
Paired t-test
data: gulls$At and gulls$Away
t = 3.1269, df = 18, p-value = 0.005826
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
27.26807 138.94246
sample estimates:
mean difference
83.10526
Calculating a standardized effect size for a paired samples t-test (and research design that includes nesting or dependency) is slightly complicated, because there are two levels at which you can describe results.
The first level is the within-subject (or within-pair, or within-gull) level, and this communicates effect size in the unit of differences (of units).
The interpretation is that, on average, variability within a single gull is about .72 standard deviations of differences of seconds.
Cohen’s D (Paired-samples t)
lsr::cohensD(x = gulls$At, y = gulls$Away, method ="paired")
[1] 0.7173615
The second level is the between-conditions variance, which is in the units of your original outcome and communicates how the means of the two conditions differ.
For that, you can use the Cohen’s d calculated for independent samples t-tests.
lsr::cohensD(x = gulls$At, y = gulls$Away, method ="pooled")
[1] 0.8137369
Which one should you use?
The first thing to recognize is that, unlike hypothesis testing, there are no standards for effect sizes. When Cohen developed his formula in 1988, he never bothered to precisely define \(\large \sigma\). Interpretations have varied, but no single method for within-subjects designs has been identified.
Most often, textbooks will argue for the within-pairs version, because this mirrors the hypothesis test.
Which one should you use?
Some1 argue the between-conditions version is actually better because the paired-design is used to reduce noise by adjusting our calculation of the standard error. But that shouldn’t make our effect bigger, just easier to detect. The other argument is that using the same formula (the between-conditions version) allows us to compare effect sizes across many different designs, which are all trying to capture the same effect.
Cohen’s D from t
This can be calculating from t-statistics, allowing you to calculate standardized effect sizes from manuscripts even when the authors did not provide them.
One sample or within-subjects for paired
\[\large d = \frac{t}{\sqrt{N-1}}\]
Independent sample
\[\large d = \frac{2t}{\sqrt{N_1+N_2-1}}\]
Finally, when you have meaningful units, also express the effect size in terms of those units. This is the most interpretable effect size available to you.
Democrats are, on average, 3.77 years older than Republicans.
Gulls take, on average, 83.11 seconds longer to approach chips when people stare at them than when people are looking away.
Assumptions: When can you not use Student’s t-test?
Recall the three assumptions of Student’s t-test:
Independence
Normality
Homogeneity of variance
Assumptions: When can you not use Student’s t-test?
There are no good statistical tests to determine whether you’ve violated the assumption of independence – it depends on how you sampled your population.
Draw phone numbers at random from a phone book?
Recruit random sets of fraternal twins?
Randomly select houses in a city and interview the person who answers the door?
Homogeneity of variance
Homogeneity of variance can be checked with Levene’s procedure. It tests the null hypothesis that the variances for two or more groups are equal (or within sampling variability of each other):
\[H_0: \sigma^2_1 = \sigma^2_2\]
Levene’s test can be expanded to more than two variances; in this case, the alternative hypothesis is that at least one variance is different from at least one other variance.
Levene’s produces a statistic, W, that is F distributed with degrees of freedom of \(k-1\) and \(N-k\).
library(car)leveneTest(age~party, data = congress, center ="mean")
Levene's Test for Homogeneity of Variance (center = "mean")
Df F value Pr(>F)
group 1 0.0663 0.797
540
Like other tests of significance, Levene’s test gets more powerful as sample size increases. So unless your two variances are exactly equal to each other (and if they are, you don’t need to do a test), your test will be “significant” with a large enough sample. Part of the analysis has to be an eyeball test – is this “significant” because they are truly different, or because I have many subjects.
Homogeneity of variance
The homogeneity assumption is often the hardest to justify, empirically or conceptually. If we suspect the means for the two groups could be different (H1), that might extend to their variances as well.
Treatments that alter the means for the groups could also alter the variances for the groups.
Welch’s t-test removes the homogeneity requirement, but uses a different calculation for the standard error of the mean difference and the degrees of freedom. One way to think about the Welch test is that it is a penalized t-test, with the penalty imposed on the degrees of freedom in relation to violation of variance homogeneity (and differences in sample size).
So that’s a bit different – the main difference here is the way that we weight sample variances. It’s true that larger samples still get more weight, but not as much as in Student’s version. Also, we divide variances here by N instead of N-1, making our standard error larger.
These degrees of freedom can be fractional. As the sample variances converge to equality, these df approach those for Student’s t, for equal N.
t.test(age~party, data = congress, var.equal = F)
Welch Two Sample t-test
data: age by party
t = 4.0688, df = 534.2, p-value = 5.439e-05
alternative hypothesis: true difference in means between group D and group R is not equal to 0
95 percent confidence interval:
1.949133 5.588133
sample estimates:
mean in group D mean in group R
59.55097 55.78233
Normality
Finally, there’s the assumption of normality. Specifically, this is the assumption that the population is normal – if the population is normal, then our sampling distribution is definitely normal and we can use a t-distribution.
But even if the population is not normal, the CLT lets us assume our sampling distribution is normal because as N approaches infinity, the sampling distributions approaches normality. So we can be pretty sure the sampling distribution is normal.
Normality
One thing we can check – the only distribution we actually have access to – is the sample distribution. If this is normal, then we might guess that our population distribution is normal, and thus our sampling distribution is normal too.
Normality can be checked with a formal test: the Shapiro-Wilk test. The test statistic, W, has an expected value of 1 under the null hypothesis. Departures from normality reduce the size of W. A statistically significant W is a signal that the sample distribution departs significantly from normal.
Normality
But…
With large samples, even trivial departures will be statistically significant.
With large samples, the sampling distribution of the mean(s) will approach normality, unless the data are very non-normally distributed.
Visual inspection of the data can confirm if the latter is a problem.
Visual inspection can also identify outliers that might influence the data.
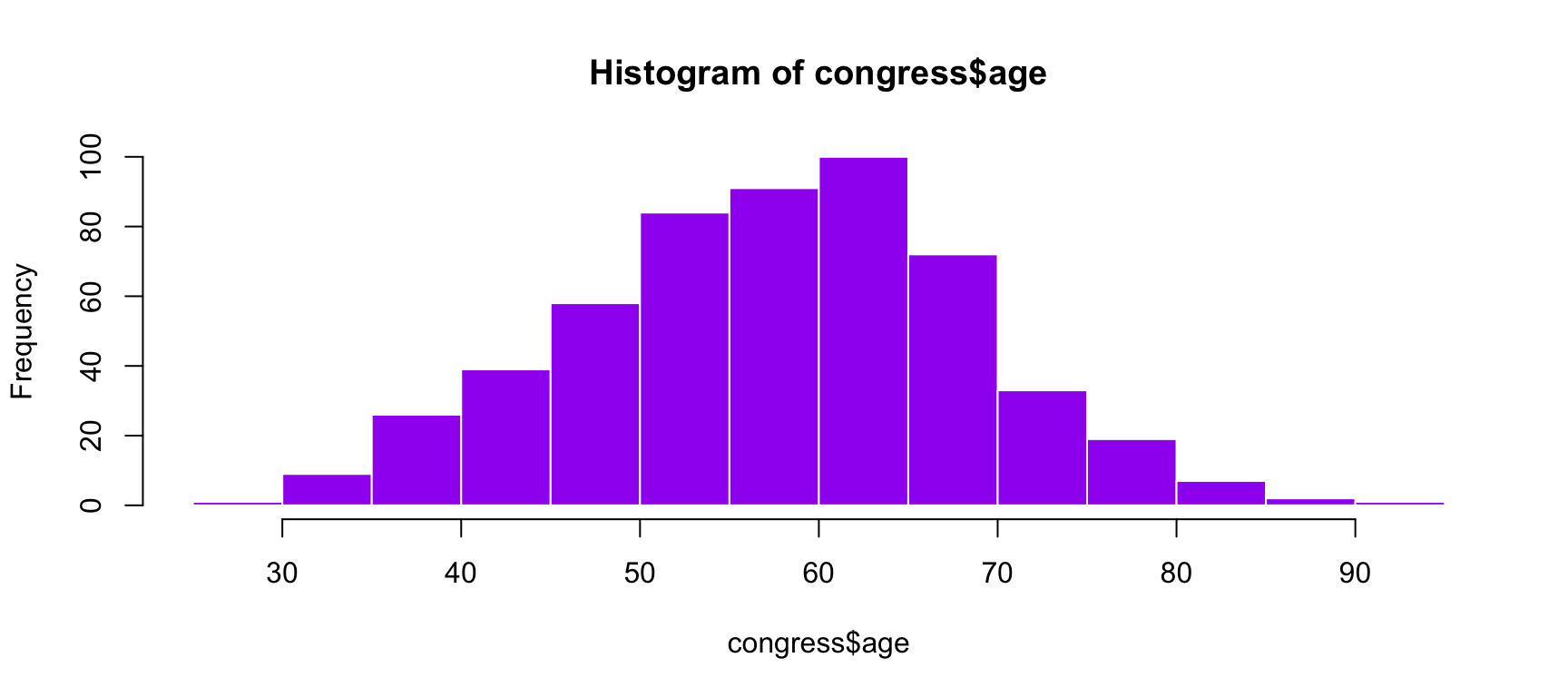
shapiro.test(x = congress$age)
Shapiro-Wilk normality test
data: congress$age
W = 0.99663, p-value = 0.3168
hist(congress$age, col ="purple", border ="white")
A common non-parametric test that can be used in place of the independent samples t-test is the Wilcoxon sum rank test. Here’s the calculation:
Order all the data points by their outcome.
For one of the groups, add up all the ranks. That’s your test statistic, W.
To build the sampling distribution, randomly shuffle the group labels and add up the ranks for your group of interest again. Repeat this process until you’ve calculated the rank sum for every possible group assignment.
wilcox.test(age~party, data = congress)
Wilcoxon rank sum test with continuity correction
data: age by party
W = 44488, p-value = 1.674e-05
alternative hypothesis: true location shift is not equal to 0
Wrap up and a look ahead
Most statistical methods propose some model, represented by linear combinations, and then tests how likely we would be to see data like ours under that model.
one-sample t-tests propose that a single value represents all the data
t-tests propose a model that two means differ
more complicated models propose that some combination of variables, categorical and continuous, govern the patterns in the data
As we think about where we’re going next term, it will be helpful to put some perspective on what we’ve covered already.
Because we’re using probability theory, we have to assume independence between trials.
independent rolls of the die
independent draws from a deck of cards
independent… tests of hypotheses?
What happens when our tests are not independent of one another?
What happens if I run multiple tests on one dataset?
The issue of independence between tests has long been ignored by scientists. It was only when we were confronted with impossible-to believe results (people have ESP) that we started to doubt our methods.
And an explosion of fraud cases made us revisit our incentive structures. Maybe we weren’t producing the best science we could…
Since then (2011), there’s been greater push to revisit “known” effects in psychology and related fields, with sobering results.
The good news is that things seem to be changing, rapidly.
Independence isn’t the only assumption we have to make to conduct hypothesis tests.
We also make assumptions about the underlying populations.
Normality
Homogeneity of variance
Sometimes we fail to meet those assumptions, in which case we may have to change course.
How big of a violation of the assumption is too much?
It depends.
How do you know your operation X measures your construct A well?
You don’t.
What should alpha be?
You tell me.
Statistics is not a recipe book. It’s a tool box. And there are many ways to use your tools.
Your job is to
Understand the tools well enough to know how and when to use them, and