Univariate Regression
Part 3
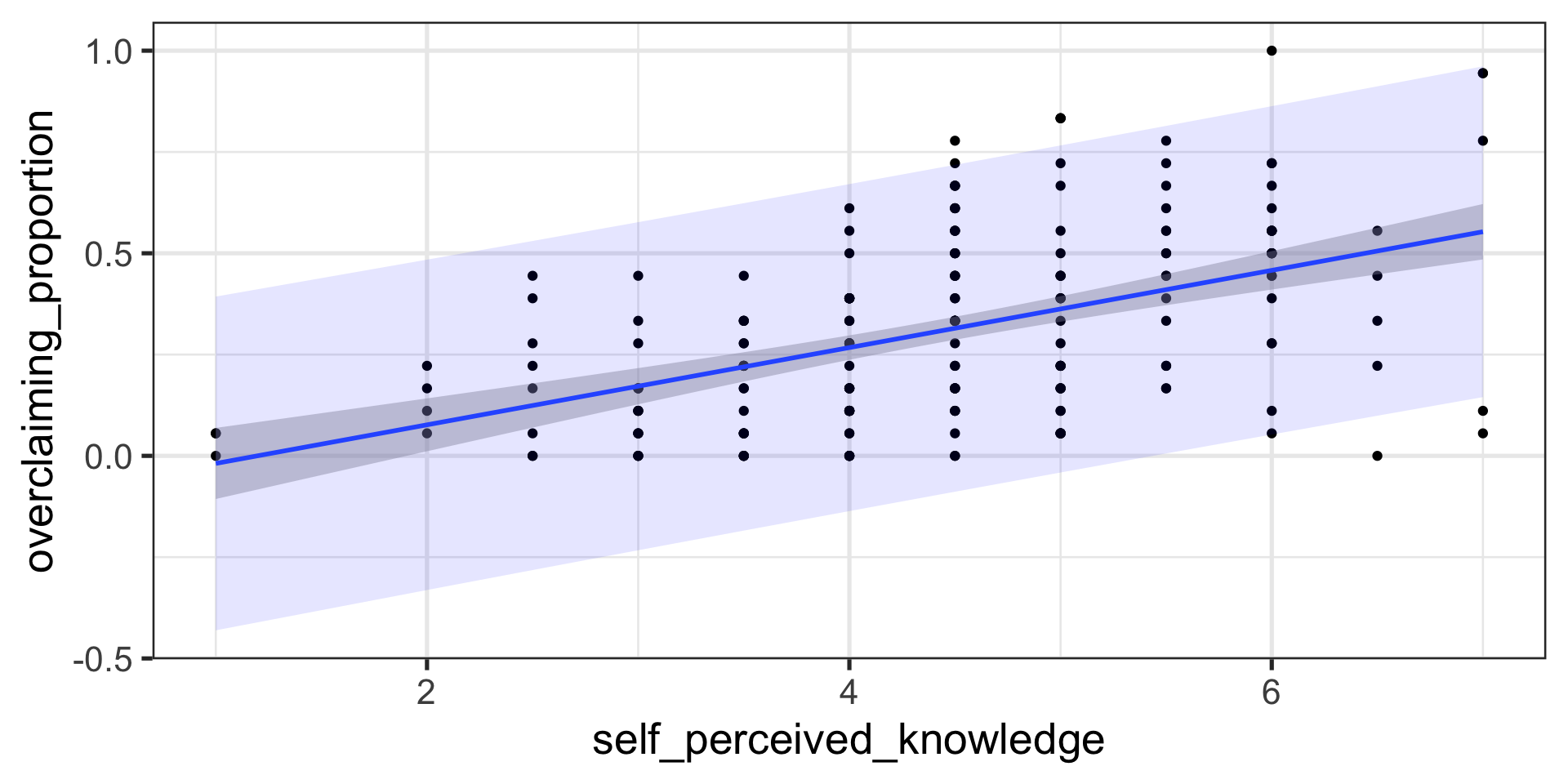
We can string these together in a figure and create confidence bands.
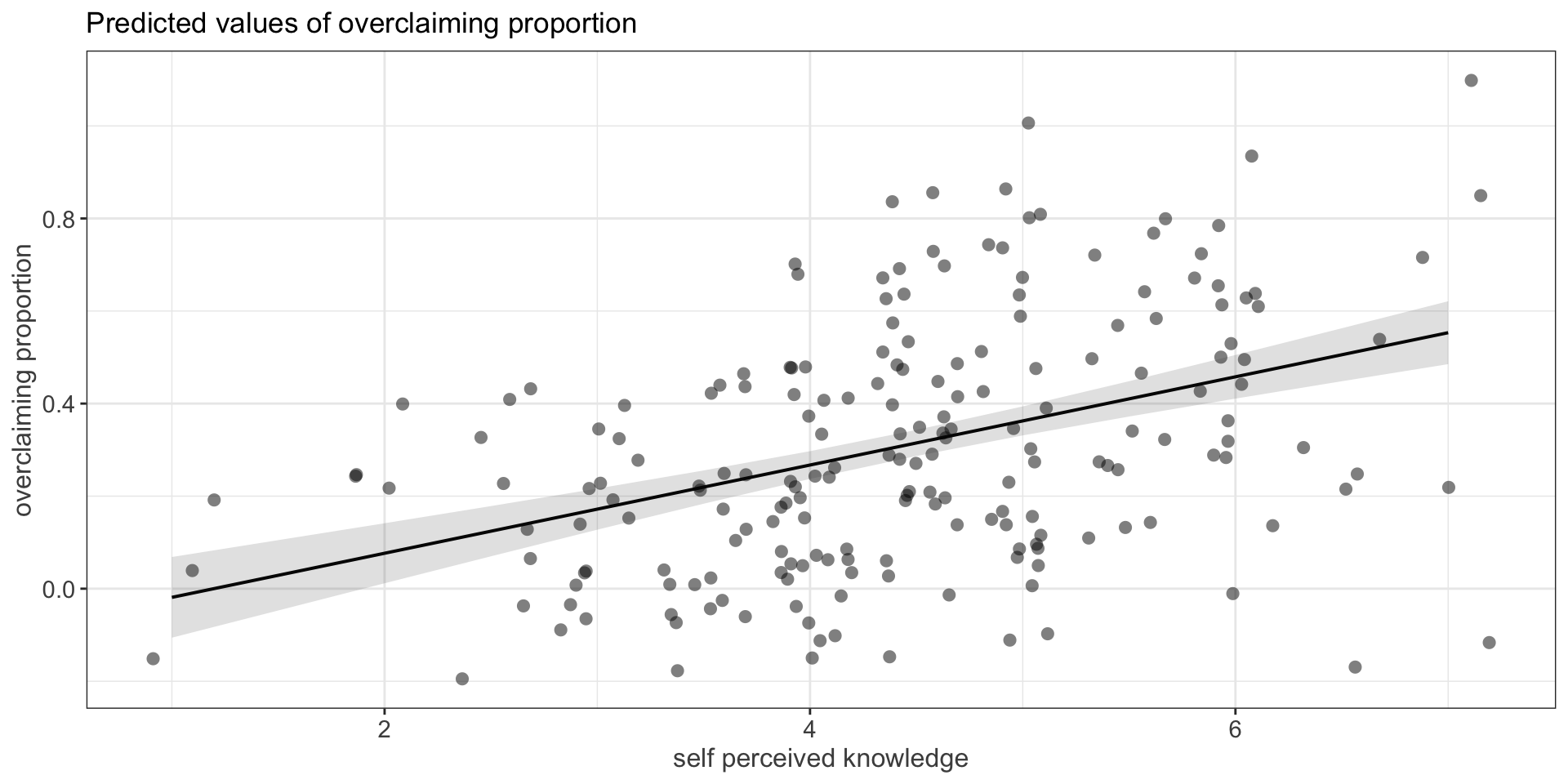
Code
expertise %>%
ggplot(aes(x = self_perceived_knowledge, y = overclaiming_proportion)) +
geom_jitter(size = .5, color = "darkgrey") +
geom_smooth(method = "lm") +
scale_x_continuous("Self-perceived knowledge") +
scale_y_continuous("Proportion of overclaiming") +
ggtitle("Using geom_smooth(se = TRUE)")+
theme_bw()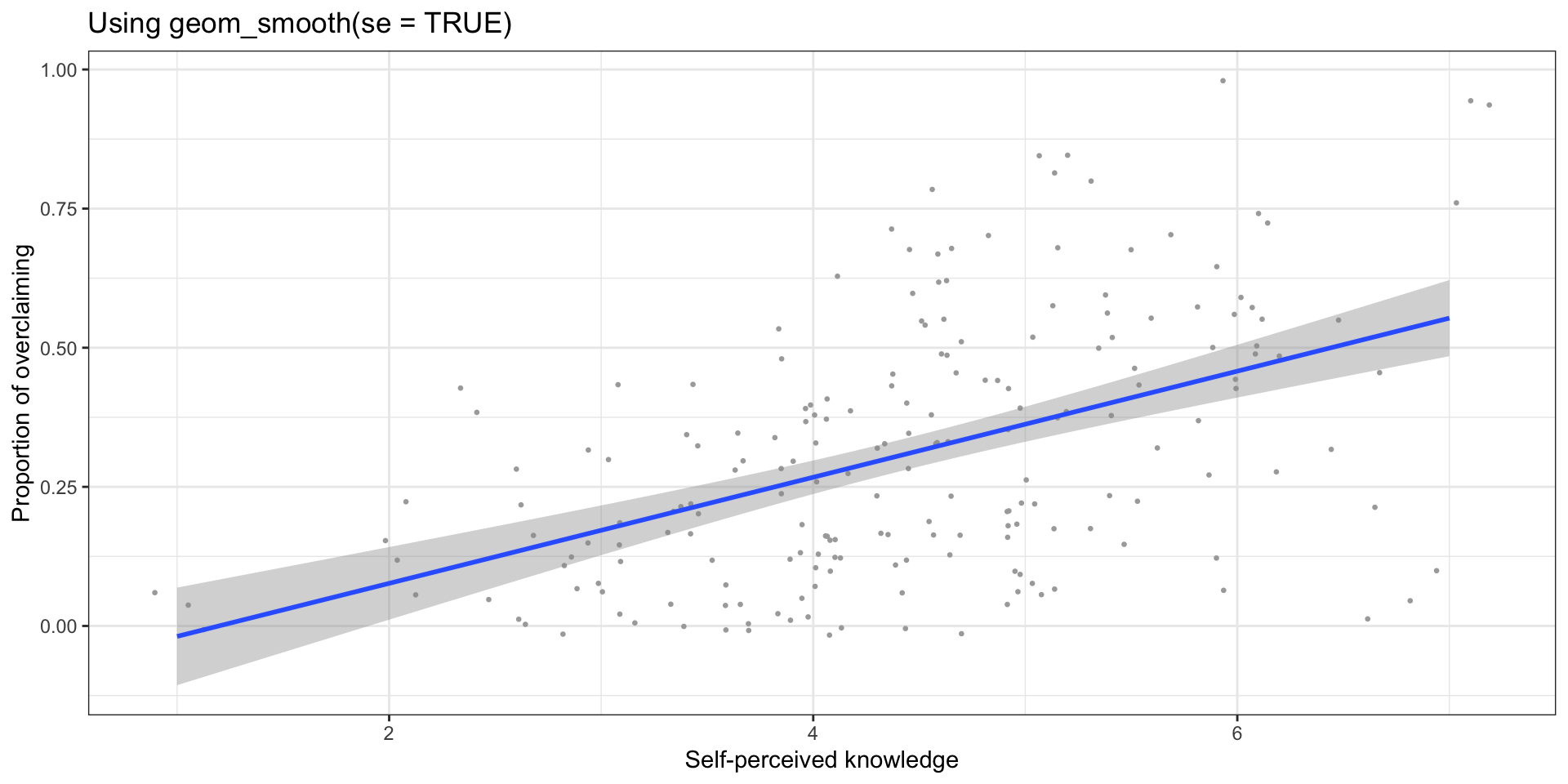
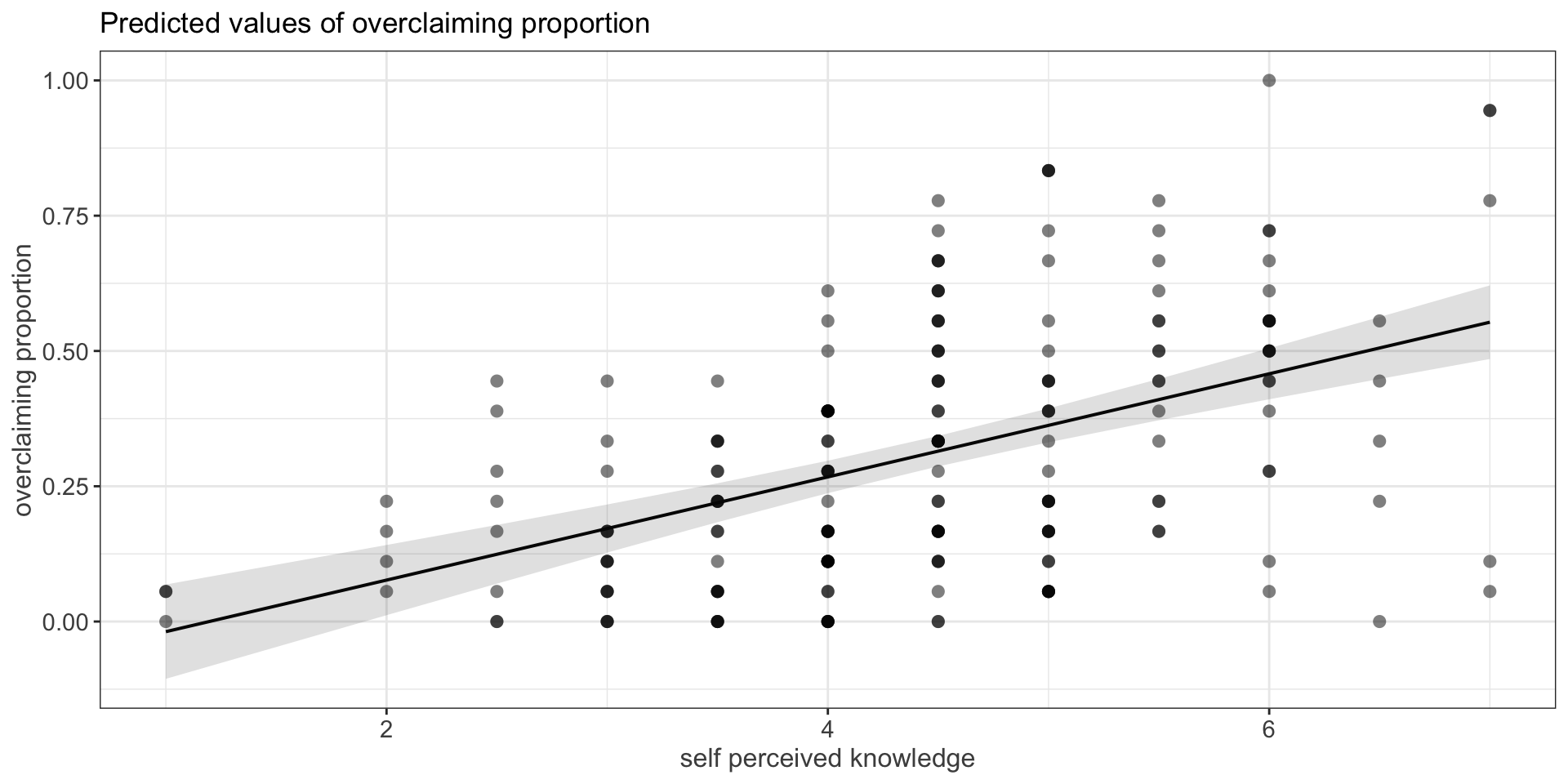
Code
expertise %>%
ggplot(aes(x = self_perceived_knowledge, y = overclaiming_proportion)) +
geom_jitter(size = .5, color = "darkgrey") +
geom_smooth(method = "lm") +
geom_abline(aes(intercept = ci[1,1], slope = ci[2,2])) +
geom_abline(aes(intercept = ci[1,2], slope = ci[2,1])) +
scale_x_continuous("Self-perceived knowledge") +
scale_y_continuous("Proportion of overclaiming") +
theme_bw()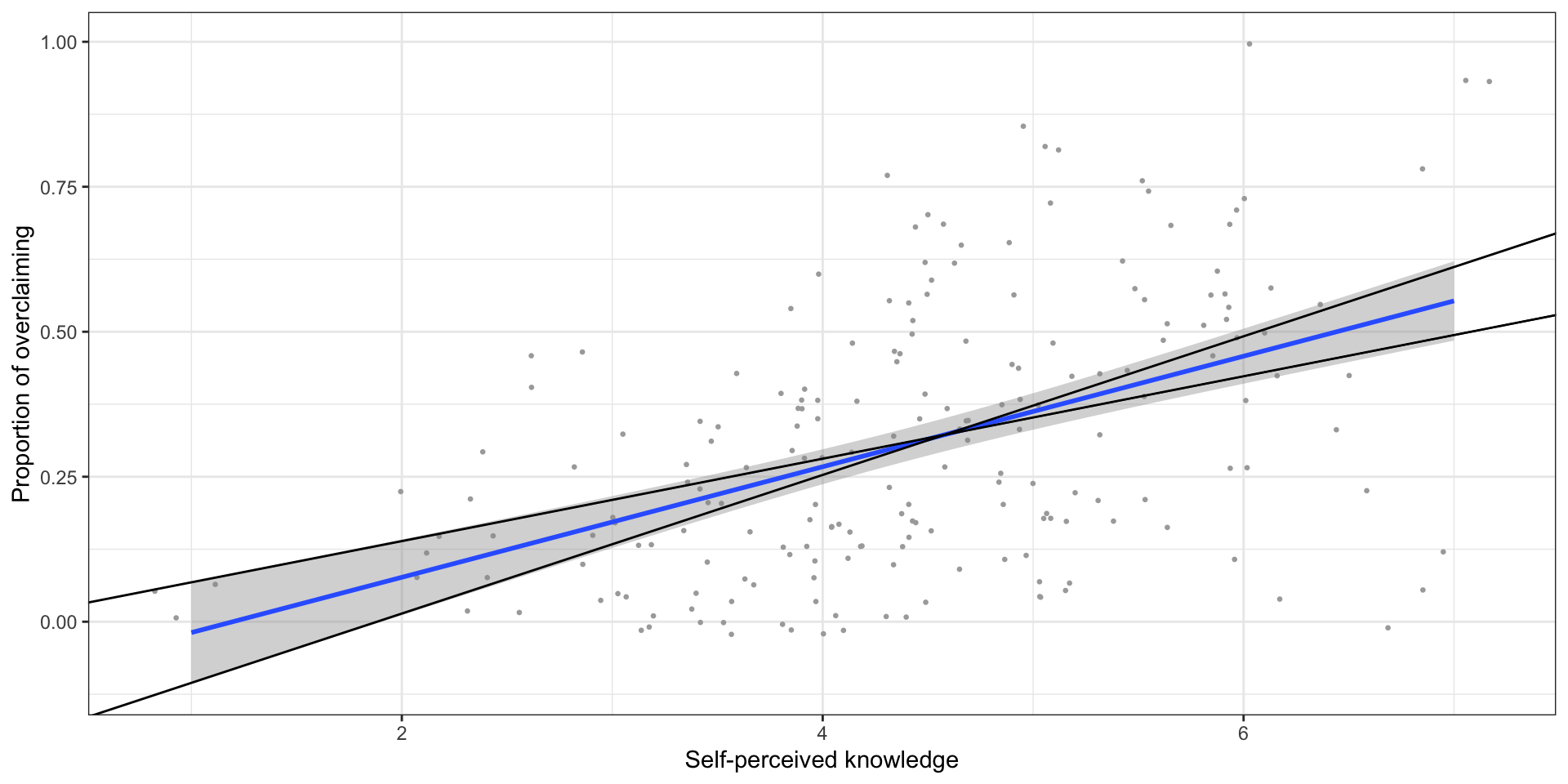
Code
set.seed(012220)
boots <- bootstrapper(100)
p <- expertise %>%
ggplot(aes(x = self_perceived_knowledge, y = overclaiming_proportion)) +
geom_smooth(method = "lm", color = NA) +
geom_jitter(alpha = 0.3) +
geom_smooth(data = boots, method = "lm", fullrange = TRUE, se = FALSE) +
theme_minimal() +
transition_states(.draw, 1, 1) +
enter_fade() +
exit_fade() +
ease_aes()
animate(p, fps = 3)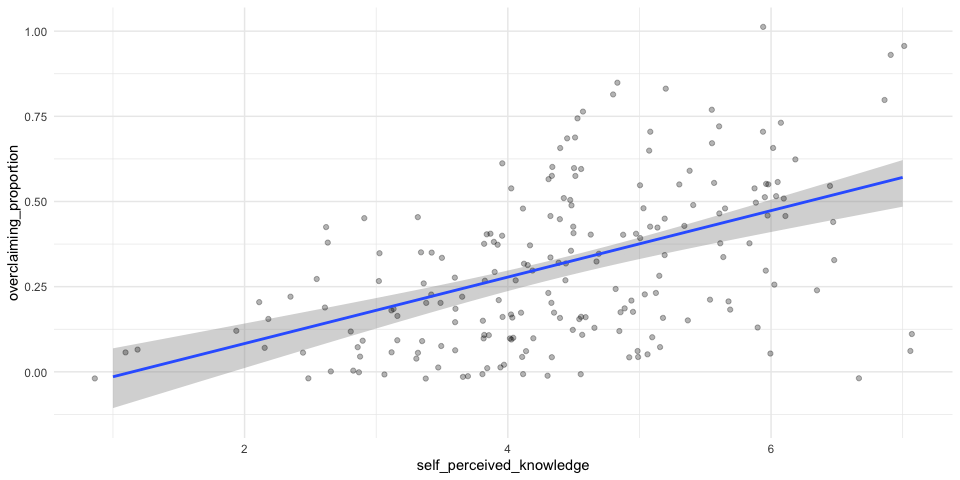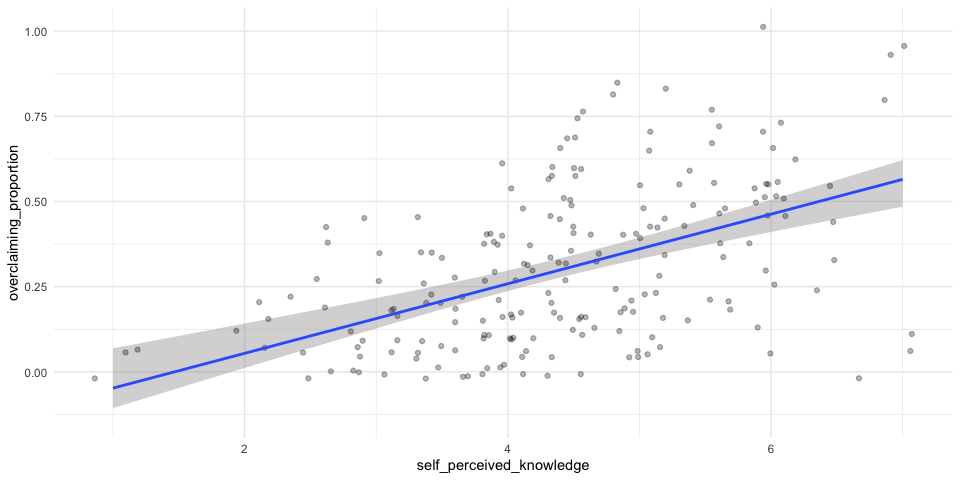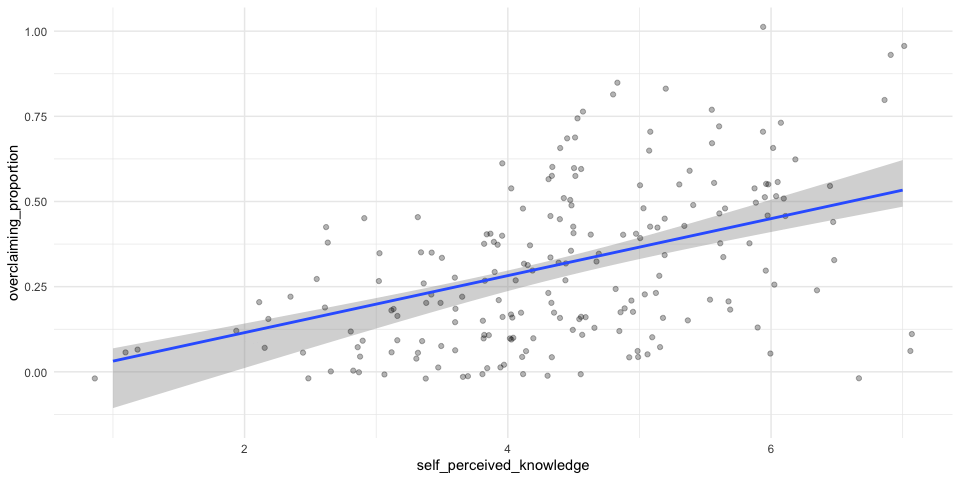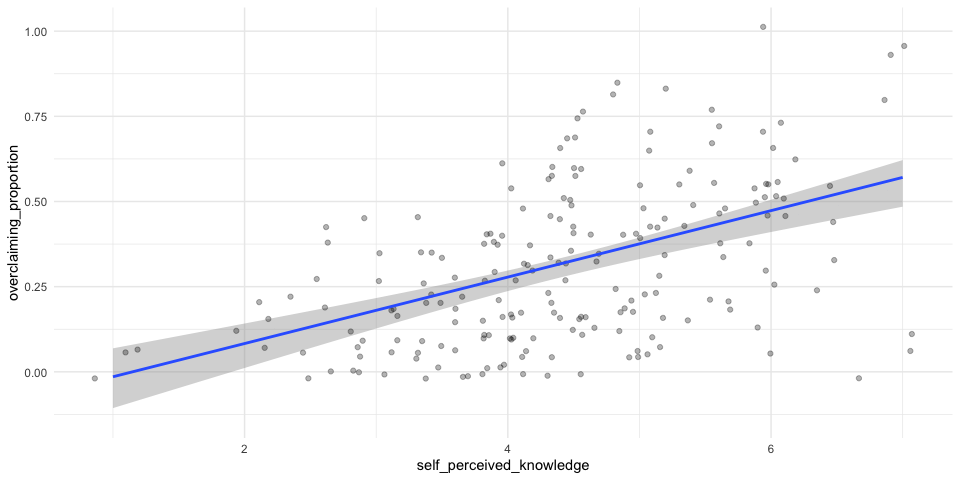
Confidence Bands for regression line
Code
set.seed(123)
px.1 <- rnorm(1000, 0, 1)
pe.1 <- rnorm(1000, 0, 1)
py.1 <- .5 + .55 * px.1 + pe.1
pd.1 <- data.frame(px.1,py.1)
px.2 <- rnorm(100, 0, 1)
pe.2 <- rnorm(100, 0, 1)
py.2 <- .5 + .55 * px.2 + pe.2
pd.2 <- data.frame(px.2,py.2)
p1 <- ggplot(pd.1, aes(x = px.1,y = py.1)) +
geom_point(alpha = .3) +
geom_smooth(method = lm, fill = "blue", alpha = .7) +
scale_x_continuous(limits = c(-3, 3)) +
scale_y_continuous(limits = c(-3, 3))
p2 <- ggplot(pd.2, aes(x=px.2, y=py.2)) +
geom_point(alpha = .3) +
geom_smooth(method=lm, fill = "blue", alpha = .7) +
scale_x_continuous(limits = c(-3, 3)) +
scale_y_continuous(limits = c(-3, 3))
library(cowplot)
plot_grid(p1, p2, ncol=2, labels = c("N = 1000", "N = 100"))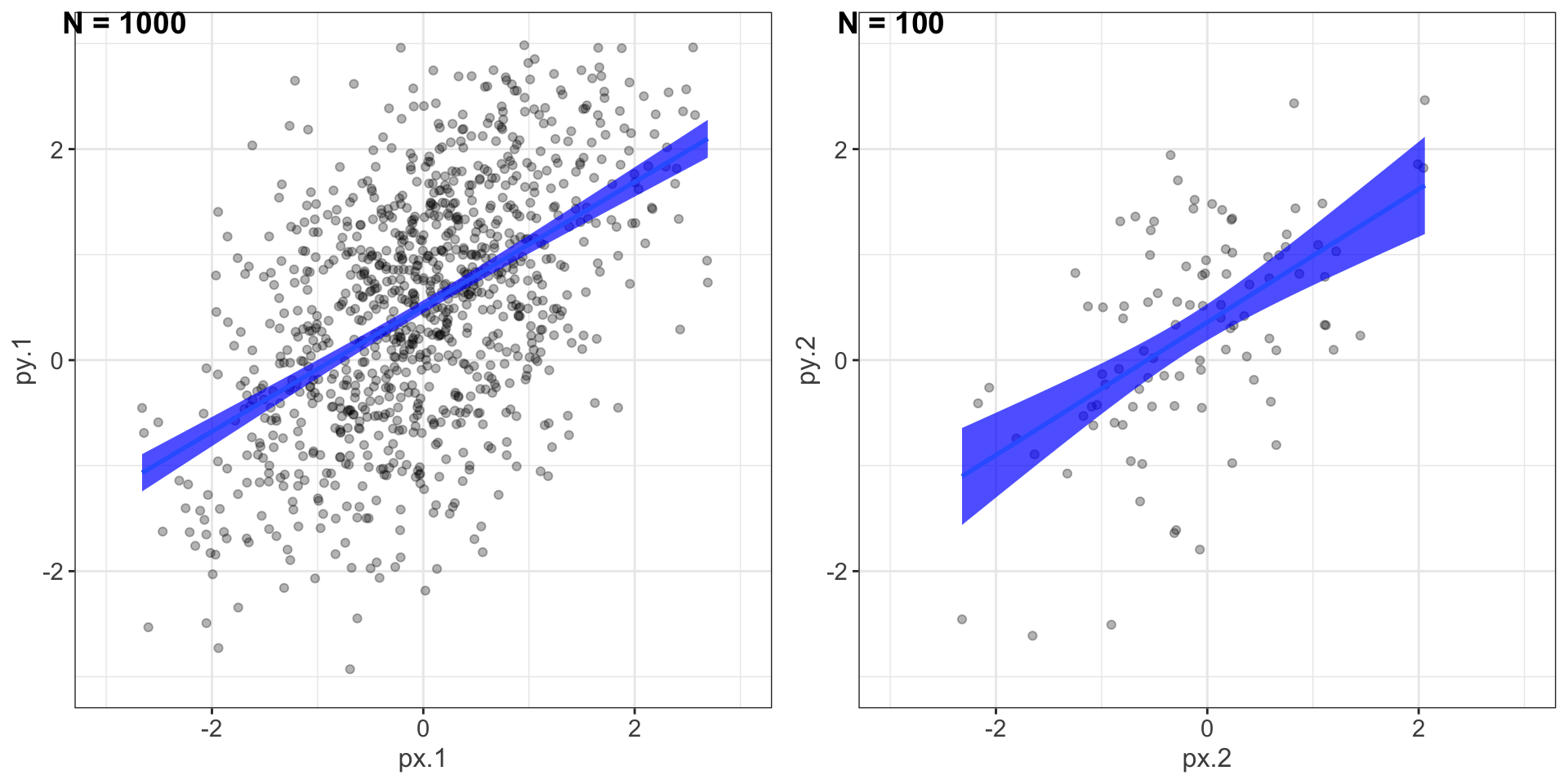
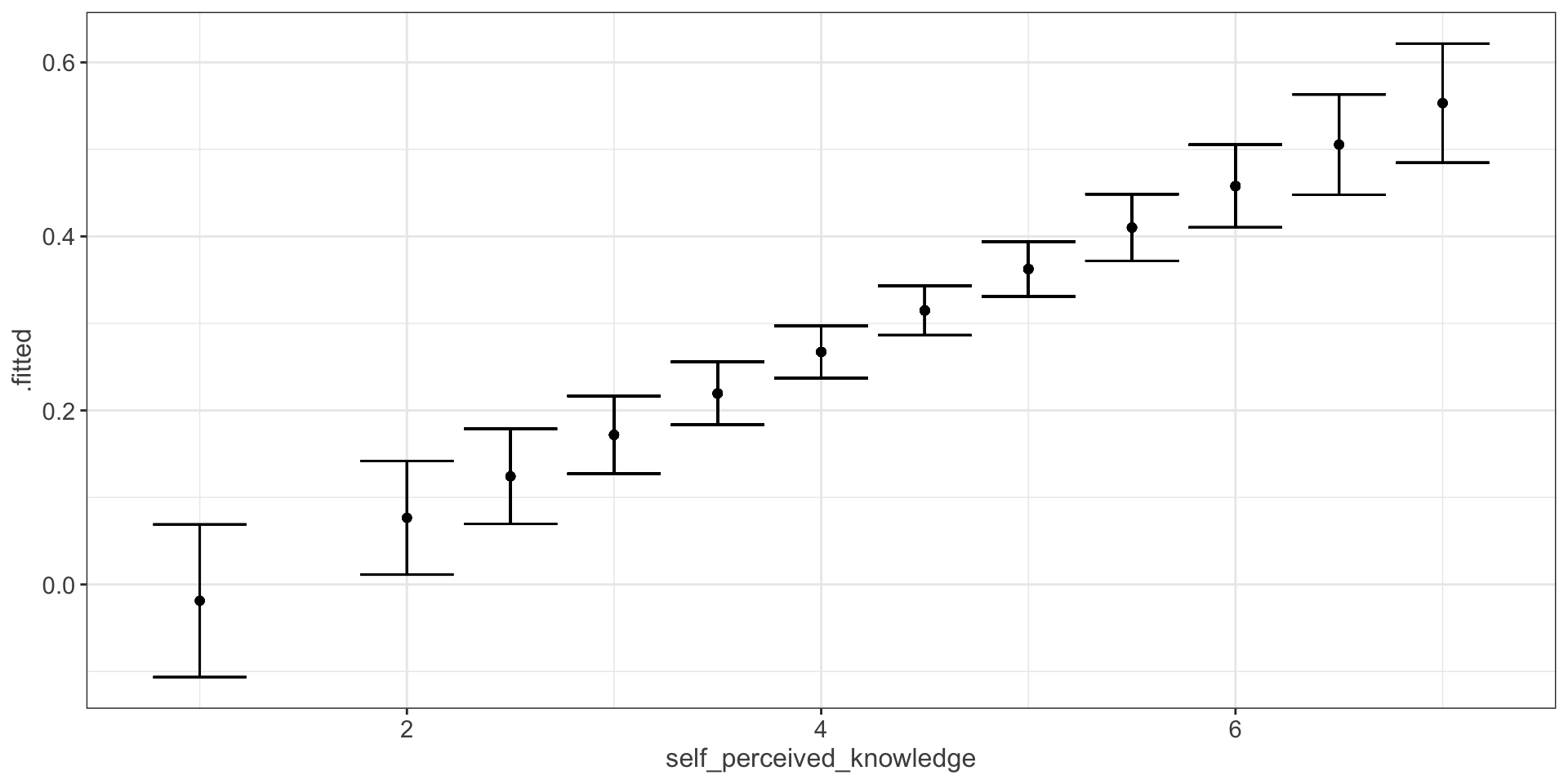
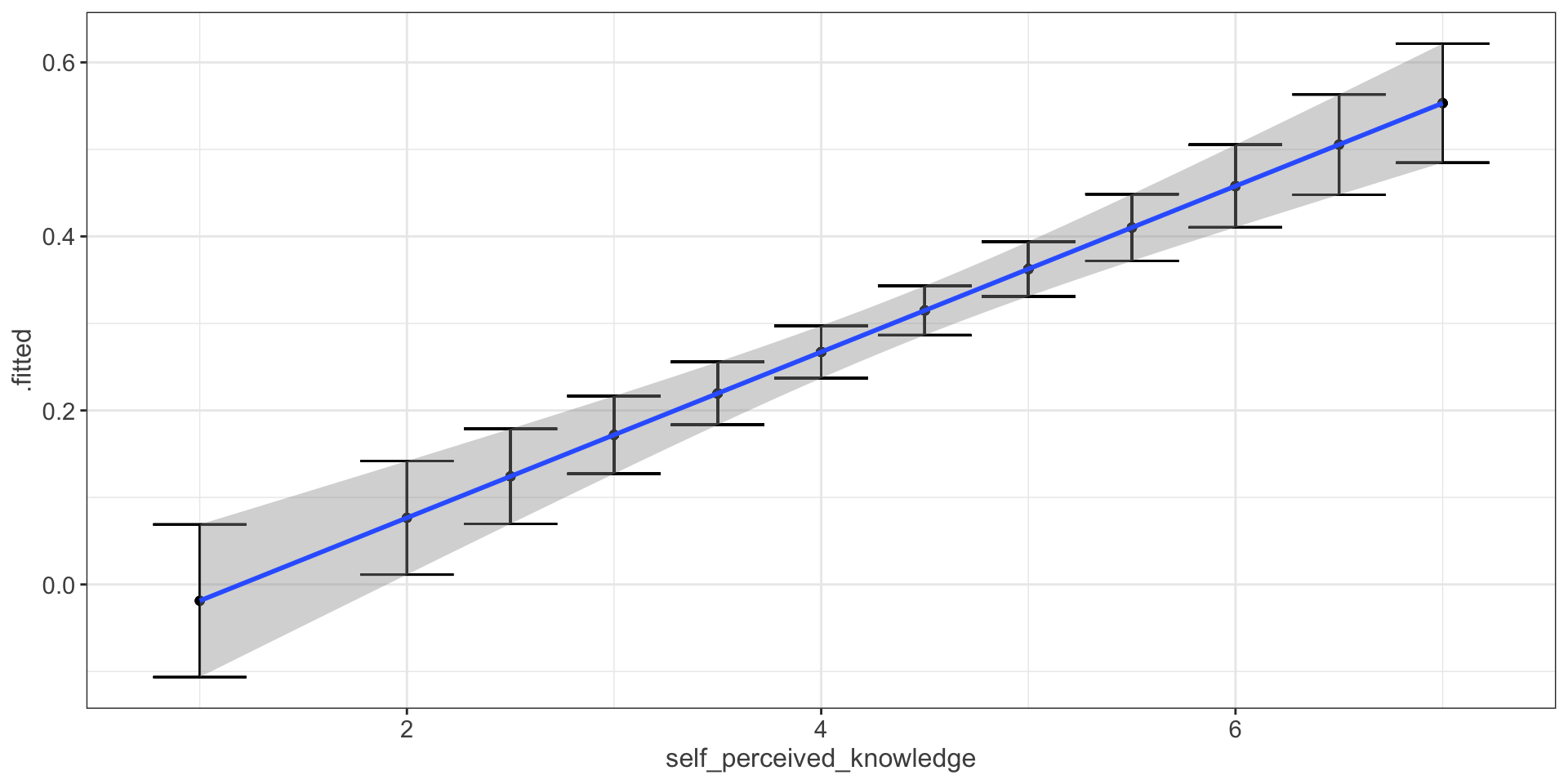
Compare mean estimate for self-perceived knowledge based on regression vs binning
Code
p1 = ggplot(expertise, aes(x=self_perceived_knowledge, y=overclaiming_proportion)) +
geom_point() +
geom_smooth(method=lm, # Add linear regression line
se=TRUE) +
scale_y_continuous(limits = c(-.12, 1.1))
p2 = expertise %>%
mutate(self_perceived_knowledge = cut_interval(self_perceived_knowledge, length = 1)) %>%
group_by(self_perceived_knowledge) %>%
summarize(m = mean(overclaiming_proportion),
s = sd(overclaiming_proportion),
n = n(),
se = s/sqrt(n),
cv = qt(p = .975, df = n-2),
moe = se*cv) %>%
ggplot(aes(x = self_perceived_knowledge, y = m)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = m-moe, ymax = m+moe)) +
scale_y_continuous("overclaiming_proportion", limits = c(-.12, 1.1))
ggpubr::ggarrange(p1, p2, align = "v")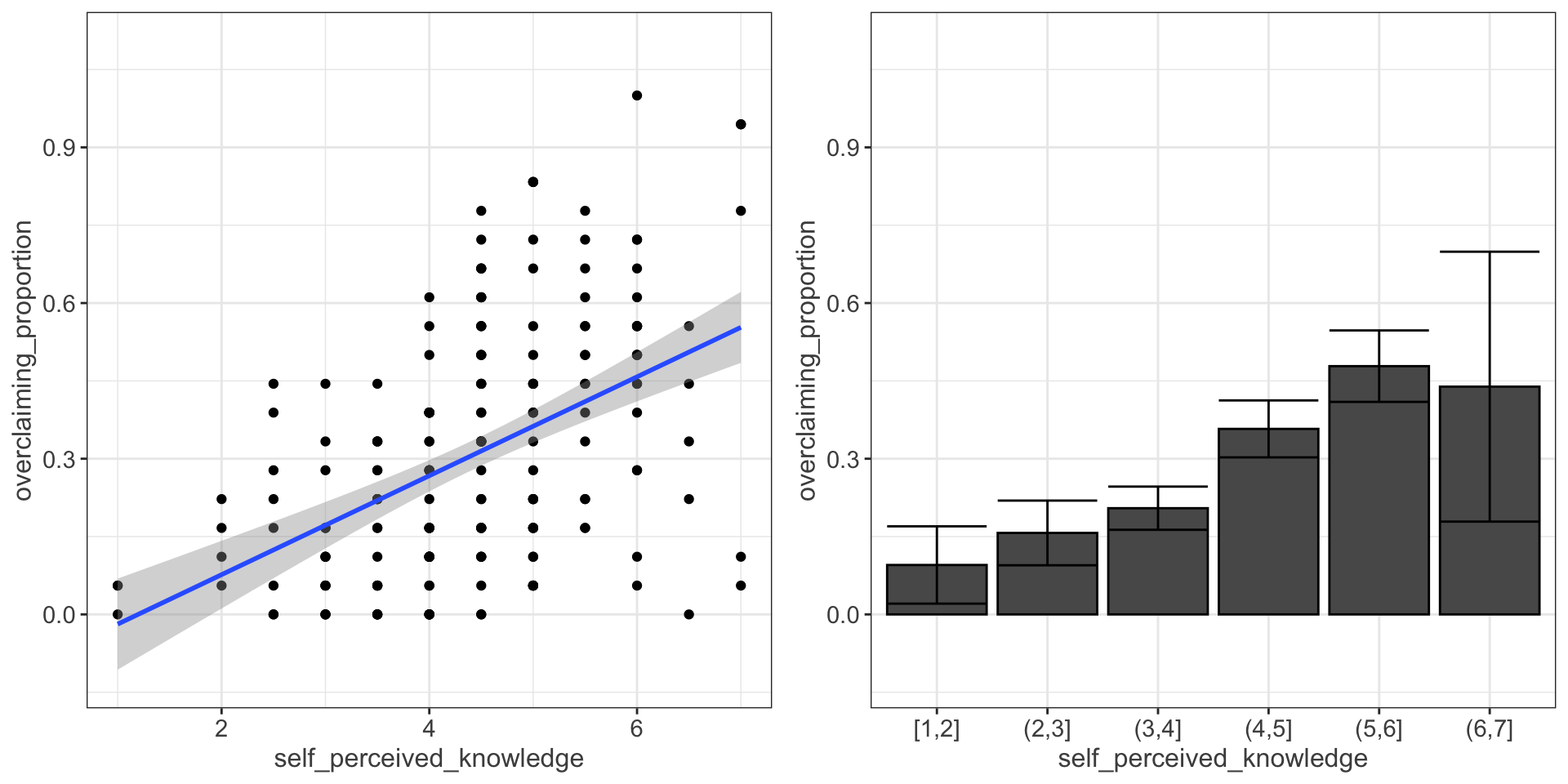
Code
temp_var <- predict(fit.1, interval="prediction")
new_df <- cbind(expertise, temp_var)
pred <- ggplot(new_df, aes(x=self_perceived_knowledge, y=overclaiming_proportion))+
geom_point() +
geom_smooth(method=lm,se=TRUE) +
geom_ribbon(aes(ymin = lwr, ymax = upr),
fill = "blue", alpha = 0.1) +
theme_bw(base_size = 20)
pred